개요
- GPU 컴퓨팅 고도화
- Model은 어떻게 관리해야 할까
- 앞으로 해결해나가야 할 문제
이전 포스팅
GPU 컴퓨팅 고도화
이전 p5 타입의 인스턴스에 gpu를 활성화까지 진행하고, 대체로 잘 동작하고 있었다.
하지만 이게 동작이 결국에 docker-compose 형태로 동작이 되고, 문제 시 Rollback 이나 CI/CD 구조내에서 많은 문제가 있었다.
그에따라 Devops 인원들이 붙어서 배포를 관리해주는 건 너무 비효율적이었다.
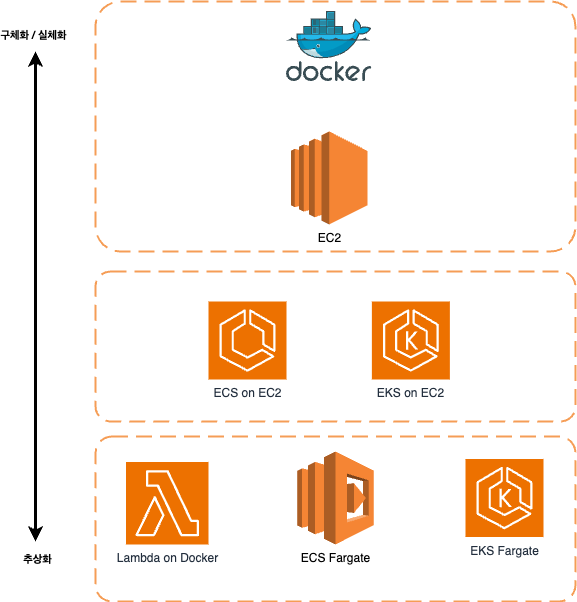
아무래도 바쁜데 이런것까지 잡아먹힐 수는 없으니, 어떻게 구성하는것이 좋을까 고민하던차에 ECS on EC2 형태가 어떨까... 싶었다.
GPU 타입의 ECS Cluster 생성
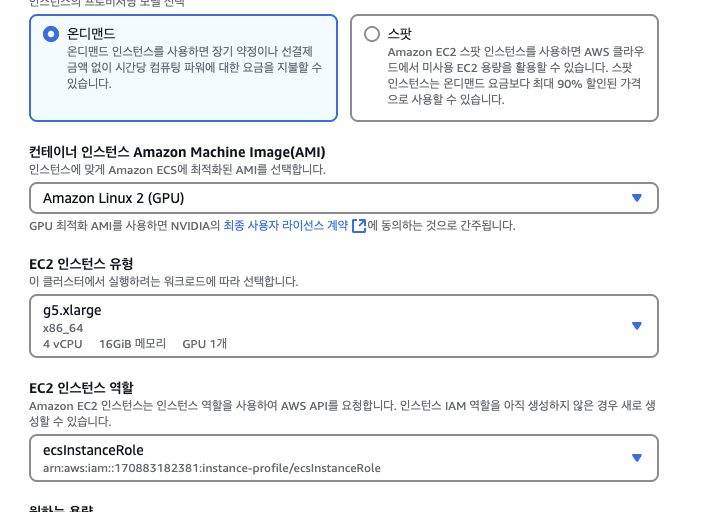
ECS Cluster 내에서 GPU 옵션이 붙어있는 EC2를 생성할 수 있었다.
원래는 EKS로 구축하려 했으나... 아직은 회사가 EKS를 받아들이기에는 시기상조
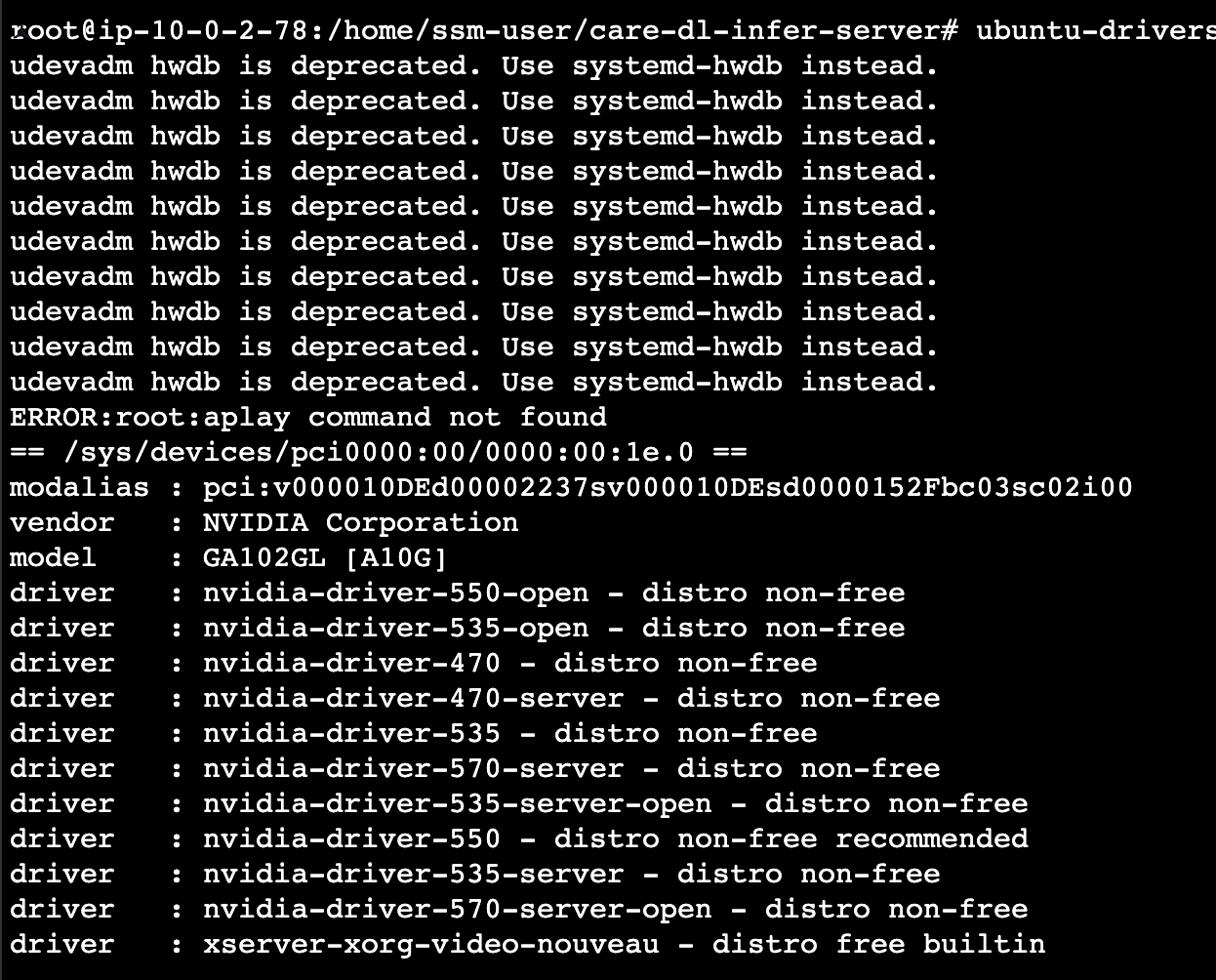
그리고 띄워봤는데, 띄우자 마자 gpu 활성화 없이 바로 gpu가 활성화 되어있네?
이전에 하루 다 날린 결과물이 허탈할 지경이었다.


좋아 목표는 아래와 같다
- 기존 CD 구성형태로 ECS 배포 관리
- ECS Agent를 활용하여 Self healing 구성
- 배포 알림 시스템 구성
GPU ECS Task Definition
{
"family": "<family name>",
"containerDefinitions": [
{
"name": "<ecs name>",
"image": "<image arn>",
"cpu": 0,
"memory": <memory>,
"portMappings": [
{
"name": "<server>",
"containerPort": <container port>,
"hostPort": 0,
"protocol": "tcp",
"appProtocol": "http"
}
],
"essential": true,
"environment": [
{
"name": "CUDA_VISIBLE_DEVICES",
"value": "0"
},
{
"name": "MKL_NUM_THREADS",
"value": "4"
},
{
"name": "TZ",
"value": "Asia/Seoul"
},
{
"name": "NUMEXPR_NUM_THREADS",
"value": "4"
},
{
"name": "GPU_SETTING",
"value": "0"
},
{
"name": "NUMEXPR_MAX_THREADS",
"value": "4"
},
{
"name": "NVIDIA_DRIVER_CAPABILITIES",
"value": "compute,utility"
},
{
"name": "OMP_NUM_THREADS",
"value": "4"
}
],
"environmentFiles": [],
"mountPoints": [],
"volumesFrom": [],
"ulimits": [
{
"name": "nofile",
"softLimit": 65536,
"hardLimit": 65536
}
],
"logConfiguration": {
"logDriver": "awsfirelens",
"options": {
"apikey": "<datadog api key>",
"compress": "gzip",
"provider": "ecs",
"dd_service": "<server>",
"Host": "http-intake.logs.datadoghq.com",
"TLS": "on",
"dd_source": "inference-server",
"dd_tags": "env:<environment>,team:<team>,role:server,app:<server>",
"Name": "datadog"
},
"secretOptions": []
},
"systemControls": [],
"resourceRequirements": [
{
"value": "1",
"type": "GPU"
}
]
},
{
"name": "datadog-agent",
"image": "public.ecr.aws/datadog/agent:latest",
"cpu": 0,
"links": [],
"portMappings": [
{
"containerPort": 8126,
"hostPort": 8126,
"protocol": "tcp"
}
],
"essential": true,
"entryPoint": [],
"command": [],
"environment": [
{
"name": "ENVIRONMENT_NAME",
"value": "<environment>"
},
{
"name": "SERVICE_NAME",
"value": "<server>"
},
{
"name": "DD_API_KEY",
"value": "<datadog api key>"
},
{
"name": "ECS_FARGATE",
"value": "true"
},
{
"name": "DD_APM_ENABLED",
"value": "true"
},
{
"name": "DD_LOGS_ENABLED",
"value": "true"
},
{
"name": "APPLICATION_NAME",
"value": "<server>"
}
],
"mountPoints": [],
"volumesFrom": [],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "<group>",
"awslogs-create-group": "true",
"awslogs-region": "ap-northeast-2",
"awslogs-stream-prefix": "ecs-service"
}
},
"systemControls": []
},
{
"name": "firelens_log_router",
"image": "amazon/aws-for-fluent-bit:stable",
"cpu": 0,
"links": [],
"portMappings": [],
"essential": true,
"entryPoint": [],
"command": [],
"environment": [
{
"name": "SERVICE_NAME",
"value": "<server>"
},
{
"name": "ENVIRONMENT_NAME",
"value": "<environment>"
},
{
"name": "APPLICATION_NAME",
"value": "<server>"
}
],
"mountPoints": [],
"volumesFrom": [],
"user": "0",
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "<group>",
"awslogs-create-group": "true",
"awslogs-region": "ap-northeast-2",
"awslogs-stream-prefix": "ecs-service"
},
"secretOptions": []
},
"systemControls": [],
"firelensConfiguration": {
"type": "fluentbit",
"options": {
"config-file-type": "file",
"config-file-value": "/fluent-bit/configs/parse-json.conf",
"enable-ecs-log-metadata": "true"
}
},
"credentialSpecs": []
}
],
"executionRoleArn": "arn:aws:iam::<accountId>:role/ecsTaskExecutionRole",
"networkMode": "bridge",
"volumes": [],
"placementConstraints": [],
"requiresCompatibilities": [
"EC2"
],
"cpu": "8192",
"memory": "24576",
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
},
"enableFaultInjection": false
}- 기존 ECS Task Definition 과 동일하나 GPU 옵션이 몇몇 추가되었다.
- 또한 DataDog 을 사용하는 만큼, 관련 SideCar도 추가하였다.
결과는? -> 잘 동작함

Model은 어떻게 관리해야 할까?
EC2 on ECS 로 구성을 하고, 나서 큰 문제는 없었으나 아래와 같은 이슈가 발생하였다.
모델 추가 변경의 건 - 첫번째 시도 (Git LFS)
Dev : 모델업데이트를 해야되는데 어떻하죠?
Devops : 모델은 VCS에 못올리나요?
Dev : 모델자체가 크기가 커서 에러가 납니다.
Devops : Git LFS로 올려야될것 같네요. 확인해보겠습니다.
모델을 생각못한건 아니지만, 아니 솔직히 생각못하긴 했다.
그래서 모델을 Git LFS를 사용하기로 했다.
git lfs install
git lfs track "~~.pt"
git lfs track "~~.lib"
git lfs track "~~.dll"
>> 산출물
## .gitattributes
* text = auto
~~.pt filter=lts diff=lfs merge=lfs -text
~~.lib filter=lts diff=lfs merge=lfs -text
~~.dll filter=lts diff=lfs merge=lfs -text근데, 이걸 설정하고 CD를 진행하려 보니 문득 이런생각이 들었다.
LFS 사용한다면?
- Git LFS를 설정 -> Git Storage 비용 발생 -> CD 내에서 LFS 관련 옵션 설정 -> 어차피 CD 할때마다 Pull / Push 함...
S3 사용한다면?
- 필요 모델 S3에 올림 -> S3 비용발생 -> CD 내에서 S3 파일다운받아서 해제
Devops : ~~님, 혹시 모델 변경이 잦을까요?
Dev : 아뇨, 잦지는 않을 것 같습니다. 현재는 개발중이라 수정이 될텐데
추후에는 한달에 한번정도만 수정 될 것 같아요
Devops : OK모델 추가 변경의 건 - 두번째 시도 ( S3 사용하자)
S3로 선택한 건, 더 편하고 비용친화적이고 관리하기 더 편할것같아서
머리아픈 LFS 보다는 S3를 선택하기로 했다.
CD 단에서 S3 데이터를 풀어서 Dockerizing 하면 끝이라고 생각했다.
## action 내에서 발췌
- name: Pull Models
run: |
aws s3 cp s3://<S3 Bucket>/models.zip .
- name: Unzip Models
run: |
unzip -o models.zip
오... 잘 동작하는데?
앞으로 해결해나가야 할 문제
- GPU 인스턴스 내 배포문제
- 현재 p5.xlarge, p5.2xlarge 타입을 사용하고 있는데
- 각각 사용할 수 있는 GPU는 1개씩이다.
- 이 얘기는 배포 시, Rolling Update가 안된다.

이 문제의 대해서는 일단 최소 인스턴스를 2개 운영하는 방식으로 구성하기로 했다.
물론 개발환경만 DeploymentConfiguration 을 조절해서 Recreate 방식으로 수정했다.
운영은 다운타임이 발생해서 일단 좋은방법이 나타날때까지 GPU 인스턴스를 2개 운영하는것으로 대체...
- 운영환경 내 비용효율화 문제
- 일단 개발환경은 SPOT 인스턴스로 대체하여, 어느정도의 비용은 낮췄다.
- 그외 더 좋은 방법이 없을까 고민했지만 -> 애초에 GPU 옵션을 사용하는 서비스에서 비용효율화... 가능할까?
- 더 좋은 방법 없을까?
- SageMaker를 고려중이다.
- 이건 좀더 공부해봐야 할 것 같다.
'Architecture > 회고 및 경험' 카테고리의 다른 글
| Vercel -> ECS 로 넘어가기 (1. 틀 잡기) (0) | 2025.05.06 |
|---|---|
| Database 권한제어 후기 (0) | 2025.04.03 |
| GPU 인스턴스 구성을 구성해보자 - 1 (0) | 2025.03.24 |
| Self Hosted -> CodeBuild (Gtihub Action) 로 넘어가기 (0) | 2025.03.16 |
| Platform Engineer의 대한 나의 생각 (0) | 2025.02.16 |