개요
- AutoScaling 동작구조 비교
- Node Scaler
- Pod Scaler
요즘 EKS를 공부하고 있는데 와... addons가 너무많다
진짜 그냥 addons 조합인 것 같다.
진짜 추후에는 K8S를 효과적으로 사용하려면 addons 버전도 리스팅해서 사용해야 할 판이다.
하여튼, AutoScaling 구조를 한번 파악해보자...
K8S 에서는 주로 Node / Pod 의 대한 스케일 정책이 존재한다. 그냥 간단히 정리하면...
- Node === EC2
- Pod === Container
사용량이 급증하면 한개의 Deployment는 여러개의 Replica ( Pod ) 를 가지게 되고 -> Pod Scaler
한 Node안에 Pod를 더이상 배치할 수 없다면? -> 노드를 증가시켜 증가된 노드에 파드를 배치한댜 -> Node Sclaer
그럼 뭐가 이렇게 많은건데...
Node Scaler
Cluster AutoScaler
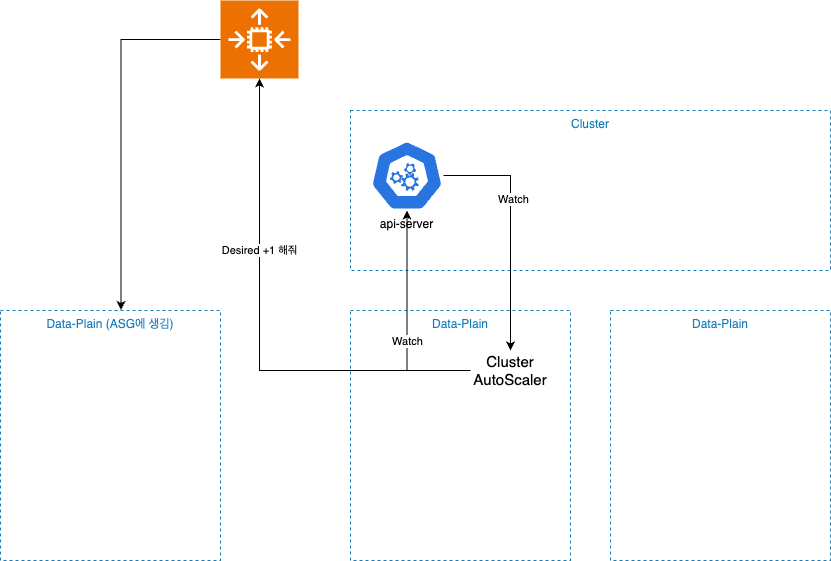
CA는 의외로 간단하다.
api-server 간의 계속 적인 통신을 진행한다.
- pod가 pending 상태가 아닌지?
- node의 사용량이 적절한지?
- nodegroup -> 각각의 pod가 어디 소속인지?
그 과정에서 이벤트가 발생하게 되면, ASG에게 요청을 한다
- desired +1
- desired -1
ASG가 대신 노드 (EC2)를 스케일아웃 , 스케일인 진행을 해준다.
Scale in 진행시에는 어떻게 될까?
- CA는 각 Node를 주기적으로 점검
- 유후노드를 발견하면 다른 Pod들을 선정된 노드로 옮길 수 있는가 평가
- 대신... 아래 Pod가 있다면 해당 노드는 제거 불가
- DeamonSet
- Larget Storage
- Static Pod
- Unreplicated Pod
- PodDisruptionBudget 위반
결국, CA는 ASG를 통해서 AutoScaling을 한다.
그리고 ASG는 알다시피 느리다...
Karpenter

카펜터도 일단 api-server와의 통신을 계속 유지한다.
- Pending 파드 감지
- 요구 리소스 분석
- 인스턴스 타입 결정 -> 가장 적절한 인스턴스 타입을 스스로 선택 (여기서 비용절감이 이뤄짐)
- EC2 인스턴스 Launch
- 노드 Join 감시
- 유후 시 EC2 Terminate
그 이후에 작업은 ASG가 아닌 본인이 직접 AWS EC2 API를 활용해서 호출한다
AWS EC2 API 는 ASG보다 더 빠르게 동작한다.
어떤게 더 좋은가?
당연히, Karpenter
- 적절한 인스턴스를 선택한다는 점에서 -> 비용 효율적
- OnDemand 뿐만 아닌, SPOT 인스턴스로 고려한다는 점
- AWS API를 사용한 방식으로 인해, ASG보다 몇배 빠르다는 점
어떻게 사용해야 할까? (이거 관련해서도 Poc 해봐야 할듯)
- 스팟인스턴스를 우선 사용하되, 없으면 온디맨드를 사용하게 끔 구성 (어차피 AutoScaling 이라 안정되면 스케일인 될거기에)
- 특정 워크로드만 GPU , ARM 인스턴스로 보내도록 제어가능
- TTLSecondsAfterEmpty 활용해서 노드 자동 회수 기능
- taints 와 labels을 사용해서 워크로드 분리
Pod Scaler
HPA (Horizontal) + metrics server 꼭 필요함
HPA는 굉장히 간단하다. CPU / Memory 또는 Custom 한 메트릭을 기반으로 파드의 개수를 조절한다
보통 Helm 으로 Deployment를 구성하면 쉽게 사용이 가능하다
- HPA는 주기적으로 Metric API에서 리소스 사용률을 확인
- TargetValue와 현재 리소스 사용률을 비교해서 적절한 Replica 수를 조정
- Deployment에 Patch를 요청해서 Replica 수를 조정
- Scheduler가 새로운 파드를 스케쥴링
스케일 계산공식은 아래와 같다
desiredReplicas = ceil[
currentReplicas × ( currentMetricValue / targetMetricValue )
]
예를들면,
현재 3개의 파드가 존재하고
CPU 사용률 평균이 80%, 목표가 50% 라면
3 * ( 80 / 50 ) = 4.8 -> 5개로 늘리는건다.
그럼...
현재 Pod가 1개고
CPU 사용률 평균이 90%고, 목표가 40% 라면
3 * ( 90 / 40 ) = 6.75 -> 7개
VPA (Vertical) -> 개발초기 때나 한번 해보려나? / 배치작업?
VPA는 파드의 실제 리소스 사용량을 모니터링 하고,
리소스 요청값과 제한값에 의해 동적으로 조정하는 컨트롤러 <- 이게 무슨 얘기야...
아... 그러니까 VPA는 기본적으로 Deployment에 기재된 request, limit 을 기준으로
데이터를 분석해서, 자동으로 request 와 limit을 조절해준다... (재배포)
약간, 아래와 같은 형태라면 VPA를 사용해봄직 하다
- 아직 서비스의 알맞은 리소스 값을 모를 때 (cpu, mem)
- 리소스 사용량이 점진적으로 변하는 서비스일때 (데이터 처리 배치작업 ...)
- 수평확장이 안되는 경우
KEDA (Event Driven 가능)
사실 이걸 제일 공부해보고 싶다
외부 이벤트에 상태를 감지해서 파드 수를 동적으로 스케일링 하는 Auto Sclaer
- 기본적으로 Keda Operator 를 활용해서 다른 외부시스템과 연동한다
- 이벤트 상태를 주기적으로 체크
- 이벤트 수량이 임계값을 초과한다면 -> HPA Replica 수 조절을 요청한다
아... HPA랑 같이 사용하는거군요...
만약... 구성하게 된다면
- NodeScaler 는 무조건 Karpetner
- PodScaler는 모두 사용할 것 같음
- 간단한 CPU / Memory 스케일링은 HPA를 활용
- VPA를 사용해서 최적값을 찾아나가게끔 모니터링 진행 (updateMode : off)
- SQS, Kafka 와 같은 메시지 큐 부하에 의해 자체적인 스케일링을 하기위해 KEDA 설정
'Architecture > K8S' 카테고리의 다른 글
| K8S - 시작 ( 용량산정 / 고려사항 ) (2) | 2025.06.02 |
|---|---|
| K8s - Karpenter (2) | 2025.06.01 |