개요
K8S AutoScaling
AutoScaler vs Karpenter
Karpenter 동작원리
Karpenter Terraform
K8S AutoScaling
K8S 는 기본적으로 Node / Pod 기반으로 서비스가 동작한다
여기서의 Node는 EC2, Pod 는 Container로 해당된다.
이때, Node 즉 EC2의 경우 서비스가 많아짐에 따라 EC2 AutoScaling을 진행하게 된다.
Pod AutoScaling 구성
Worker Node에 Pod가 많아짐
기존 Node 용량보다 Pod가 많아질 경우, EC2 Node 가 더 생김
그럼 그냥 EC2 AutoScaling 을 Default 하게 사용하면 안되나?
그렇게 써도 되긴하는데, 좀더 효율적인 방법의 AutoScaling 방법을 사용해야 한다.
EC2 Launch Template vs AutoScaler vs Karpenter
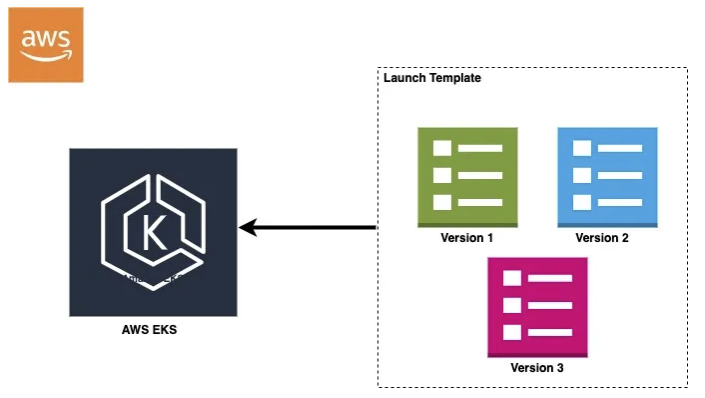
EC2 Launch Template + ASG
EC2 Launch Template + ASG
가장 기본적인 방식이다.
EC2 인스턴스 그룹을 미리 정의해두고, 트래픽에 따라 인스턴스를 수동 / 자동으로 확장할 수 있다.
Kubernetest 의 Pod 상태를 직접적으로 알기 어렵기 때문에 과잉 할당으로 인한 불필요한 비용이 발생할 여지가 존재함
운영자가 직접 Scale 정책을 설계해야 하기때문에, 유지관리 비용이 크다.
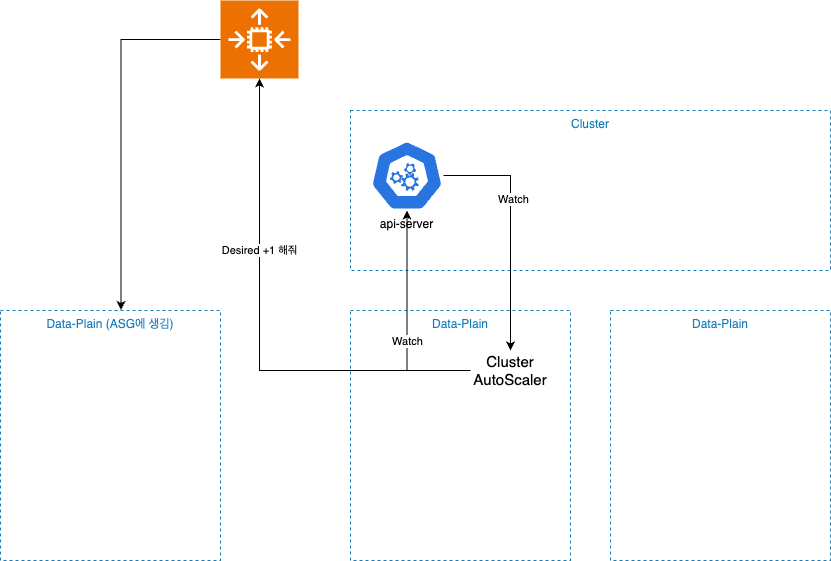
AutoScaler
AutoScaler
K8S 에서 주로 사용하는 AutoScaling 컴포넌트
Pod가 Node에 스케쥴링되지 못할 때 -> 필요에 따라 EC2를 자동으로 생성한다.
ASG완 연동되어 작동하며, 기본적으로 NodeGroup 단위로 동작한다.
다만, 아래와 같은 단점이 존재한다.
각 NodeGroup의 대한 설정이 필요
리소스 낭비가 발생하기 쉽다.
스케일 속도가 느리다 ( AutoScaling 자체가 기본적으로 느림 )
Karpenter (밑에 사진 참조)
AWS 가 만든 오픈소스 Kubernetes AutoScaler (참 잘만듬 )
Pod 스케쥴링 요청에 따라, 가장 적합한 인스턴스 타입과 크기를 실시간으로 계산하여 자동 생성한다
NodeGroup이 아닌, 단일 프로비저닝 정책만으로도 다양한 EC2 타입을 활용할 수 있다. (SPOT도 가능)
프로비저닝 속도가 빠르다 (awscli 사용해서 EC2를 생성하기 때문에 AutoScaling 보다 빠르다 )
그냥 결론적으로 보면... (주관적)
빠른가? -> Karpenter >>>>>> Launch Template == AutoScaler
비용최적화로 EC2를 설정하는가? -> Karpenter
설정이 어렵나? -> Karpenter == Launch Template == AutoScaler
Karpenter 동작원리
pod 생성 후 -> node attach
Academic 한 이론으로는 아래와 같다.
Pending Pod를 감지한다 -> Kubernetes에 Scheduling Cycle 중 스케쥴되지 못한 Pod를 감지한다
Pod의 요구 리소스를 분석한다 (이 Pod를 수용할 수 있는 최적의 인스턴스를 구하는 단계 )
CPU / Memory / GPU 리소스 요구량
NodeSelector, Trolerations, Affinity 제약 조건
Storage / Zone / OS 특수 요구사항
적합한 인스턴스 타입 탐색
리전 및 가용역역
on-Demand or SPOT 인스턴스 여부
인스턴스 프로비저닝
위 단계를 지나치고 선택된 EC2 타입을 직접 API로 생성 (아주 빠름)
AMI Kubernetes Kubelet IAM Role, SG, Subnet 설정
Pod 스케쥴링 및 Node 연결
생성된 EC2 인스턴스를 K8S Node로 Join
Pending Pod를 해당 Node에 스케쥴링
유후 Node 감지 및 제거
consolidation, ttlSecondsAfterEmpty, expiration 등의 설정으로 유휴 노드 제거 전략 조절 가능
하지만 난, 저걸 이해못함 -> 내가 이해한 바로는 ...
처음 카펜터를 구성하면 4가지? 를 생성 및 참조하게된다.
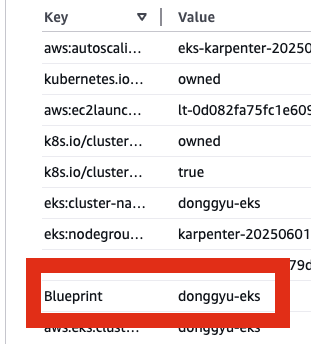
태그 참조
Karpenter IRSA
Karpenter Controller
Karpenter Provisioner
태그참조
카펜터는 참 신기한 놈이다.
카펜터를 사용하겠다를 태그를 활용해서 구성한다.
카펜터가 구성되는 EC2
카펜터를 사용해서 Provisioning 되는 EC2의 SG
카펜터를 사용해서 Provisioning 되는 EC2가 속한 Subnet
에 올바른 Tag가 기입이 되어야 한다.
설정마다 다르겠지만, 나는 Blueprint
Karpenter IRSA
k8s에 장점이자 단점인, Service Account이다
즉, pod의 권한을 IAM Role로서 제한을 할 수 있다.
Node안에는 다양한 서비스의 Pod들이 떠있다. 그렇기 때문에 IRSA를 사용해서
namespace 별로, 각각 다른 serviceAccount (SA) 를 만들고 해당 Pod에 각각 다른 IAM Role을 부여해서 사용한다.
Karpenter Controller (언제 노드를 만들까?)
Deployment
실제로 노드를 프로비저닝하는 실행 컴포넌트
기본적으로 1개의 replica로 실행된다 (namespace = karpenter)
Karpenter Provisioner (어떤 노드를 만들까?)
Custom Resource (CR)
노드 프로비저닝의 정책을 정의하는 설정 컴포넌트 <- 여기에 적힌 구성대로 Karpenter가 최적의 EC2를 찾아줌
Karpenter Terraform
variable "eks_attr" {
default = {
"name" : "donggyu-eks"
"version" : "1.32"
}
}
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.31"
cluster_name = lookup(var.eks_attr, "name")
cluster_version = lookup(var.eks_attr, "version")
cluster_endpoint_public_access = true // 외부에서 접근 가능
cluster_endpoint_private_access = true // 내부에서 접근 가능
create_cluster_security_group = false
create_node_security_group = false
# Optional: Adds the current caller identity as an administrator via cluster access entry
enable_cluster_creator_admin_permissions = true
vpc_id = local.vpc.vpc_id
subnet_ids = values(local.vpc.was_subnets)
# EKS Addons
cluster_addons = {
coredns = {
most_recent = true
}
kube-proxy = {
most_recent = true
}
vpc-cni = {
most_recent = true
}
aws-ebs-csi-driver = {
most_recent = true
}
# eks-pod-identity-agent = {}
}
eks_managed_node_groups = {
karpenter = {
instance_types = ["t4g.medium"]
ami_type = "AL2_ARM_64"
min_size = 2
max_size = 5
desired_size = 2
# capacity_type = "SPOT"
iam_role_additional_policies = {
"AmazonSSMManagedInstanceCore" = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}
}
}
node_security_group_additional_rules = {
ingress_karpenter_webhook_tcp = {
description = "Control plane invoke Karpenter webhook"
protocol = "tcp"
from_port = 8443
to_port = 8443
type = "ingress"
source_cluster_security_group = true ## 해당 규칙의 소스를 cluster가 가지고있는 보안그룹으로 지정 (node간 통신허용)
}
}
tags = merge({
Blueprint = lookup(var.eks_attr, "name")
}, {
"karpenter.sh/discovery" = lookup(var.eks_attr, "name")
})
}
################################################################
######## karpenter
################################################################
resource "aws_iam_instance_profile" "karpenter" {
name = "KarpenterNodeInstanceProfile-${module.eks.cluster_name}"
role = module.eks.eks_managed_node_groups["karpenter"].iam_role_name
}
################################################################
######## aws-auth
################################################################
module "eks_aws_auth" {
source = "terraform-aws-modules/eks/aws//modules/aws-auth"
version = "~> 20.0"
manage_aws_auth_configmap = true
aws_auth_roles = [
{
rolearn = "arn:aws:iam::${data.aws_caller_identity.current.account_id}:role/AWSReservedSSO_AdministratorAccess_18f0ecd34fab4ea6"
username = "admin"
groups = ["system:masters"]
},
{
rolearn = module.eks.eks_managed_node_groups["karpenter"].iam_role_arn
username = "system:node:{{EC2PrivateDNSName}}"
groups = ["system:nodes", "system:bootstrappers"]
}
]
aws_auth_users = [
{
userarn = "arn:aws:iam::${data.aws_caller_identity.current.account_id}:user/admin"
username = "admin"
groups = ["system:masters"]
}
]
}## karpenter pod가 AWS에 접글할 수 있도록 IRSA를 생성
module "karpenter_irsa" {
source = "terraform-aws-modules/iam/aws//modules/iam-role-for-service-accounts-eks"
version = "~> 4.21.1"
role_name = "karpenter-controller-${module.eks.cluster_name}"
attach_karpenter_controller_policy = true
karpenter_controller_cluster_id = module.eks.cluster_arn
karpenter_controller_node_iam_role_arns = [
module.eks.eks_managed_node_groups["karpenter"].iam_role_arn
]
karpenter_controller_ssm_parameter_arns = [
"arn:aws:ssm:*:*:parameter/aws/service/eks/optimized-ami/*"
]
oidc_providers = {
ex = {
provider_arn = module.eks.oidc_provider_arn
namespace_service_accounts = ["karpenter:karpenter"]
}
}
}
# EKS 클러스터 접근 권한을 위한 IAM 정책
resource "aws_iam_policy" "karpenter_eks_access" {
name = "karpenter-eks-access-${module.eks.cluster_name}"
description = "Policy for Karpenter to access EKS cluster"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = [
"eks:DescribeCluster",
"eks:ListClusters",
]
Resource = module.eks.cluster_arn
},
{
Effect = "Allow",
"Action" : [
"ec2:RunInstances",
"ec2:TerminateInstances",
"ec2:DescribeSpotPriceHistory",
"pricing:GetProducts"
],
"Resource" : "*"
}
]
})
}
# IAM 정책을 Karpenter IRSA 역할에 연결
resource "aws_iam_role_policy_attachment" "karpenter_eks_access" {
role = module.karpenter_irsa.iam_role_name
policy_arn = aws_iam_policy.karpenter_eks_access.arn
}
# karpenter_helm.tf
resource "helm_release" "karpenter" {
name = "karpenter"
repository = "oci://public.ecr.aws/karpenter"
chart = "karpenter"
version = "v0.27.0"
namespace = "karpenter"
create_namespace = true
set {
name = "serviceAccount.annotations.eks\\.amazonaws\\.com/role-arn"
value = module.karpenter_irsa.iam_role_arn
}
set {
name = "settings.aws.clusterName"
value = module.eks.cluster_name
}
set {
name = "settings.aws.defaultInstanceProfile"
value = "KarpenterNodeInstanceProfile-${module.eks.cluster_name}"
}
set {
name = "settings.aws.interruptionQueueName"
value = module.eks.cluster_name
}
wait = true
}
# karpenter_manifest.tf
resource "kubectl_manifest" "karpenter_node_template" {
yaml_body = file("${path.module}/karpenter.yaml")
depends_on = [helm_release.karpenter]
}apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: provisioner
spec:
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: [ "t4g.medium" ]
- key: "topology.kubernetes.io/zone"
operator: In
values: [ "ap-northeast-2a", "ap-northeast-2b", "ap-northeast-2c" ]
- key: "eks.amazonaws.com/capacityType"
operator: In
values: [ "ON_DEMAND" ]
- key: "kubernetes.io/arch"
operator: In
values: [ "arm64" ]
# 생성할 인스턴스의 최대 리소스
limits:
resources:
cpu: "10"
memory: 20Gi
# nvidia.com/gpu: 16
# karpenter 프로비저닝 메커니즘 사용
# ttlSecondsAfterEmpty 와 consolidation 은 동시에 사용 불가
# consolidation:
# enabled: true
# ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
ttlSecondsAfterEmpty: 30
# 생성된 인스턴스(worker node)에 지정되는 label
labels:
environment: donggyu-eks
managed-by: karpenter
Blueprint: donggyu-eks
# 생성된 인스턴스(worker node)에 지정되는 taints
# taints:
# - key: nvidia.com/gpu
# value: "true"
# effect: NoSchedule
provider:
# 생성한 인스턴스에 어느 보안 그룹을 적용할 것인지 보안 그룹의 태그로 지정
securityGroupSelector:
Blueprint: donggyu-eks
# 어느 서브넷에 인스턴스를 생성할 것인지 태그로 지정
subnetSelector:
environment: donggyu-eks
managed-by: karpenter
# 생성된 인스턴스의 태그를 지정
tags:
Blueprint: donggyu-eks