개요
- GPU 인스턴스를 구축해보자
- GPU 활성화 하기
- Docker 내에서는 왜 안되지?
- Docker 에서도 GPU 활성되게 하기
GPU 인스턴스를 구축해보자
최근 추론모델을 학습하기 위해서, GPU를 사용하는 인스턴스가 필요했다.
가만보자...

현재 회사에서 알맞은 스펙은 Amazon EC2 g5로 진행하기로 했다.
테스트하고, 비교한 결과는 내부적인 자료라서 공유하기는 애매하고....
많은 테스트를 통해서 g5.2xlarge 를 사용하기로 하였다.
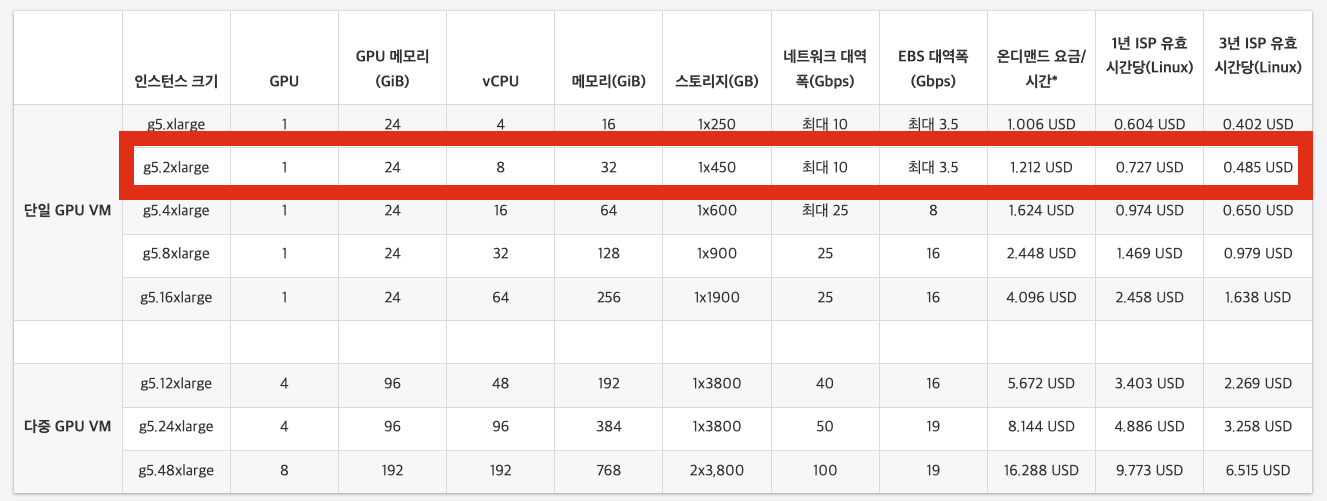
가격은 시간 당 $ 1.212
하루에 1.212 * 24 = $ 29
한달에 30 * 29 = $ 872 (매우 비싸다...)
GPU 활성화하기
EC2 기본적인 스펙은 아래와 같다.
| 운영체제 | Computing | Storage |
| ubuntu | g5.2xlarge | 150 GB (gp3) |
사실 처음에 gpu 인스턴스를 구축하면, 자동으로 gpu가 있는건 줄 알았는데,
driver를 직접 설치하고 구성을 해야 하더라...
이것도 모르고 왜 느리지?... 했었따.
기본적인 Ubuntu 환경 세팅
sudo apt-get update -y
sudo apt install gcc -y
sudo apt-get install linux-headers-$(uname -r)
sudo apt install ubuntu-drivers-common -y
ubuntu-drivers devices
ubuntu-drivers devices를 하게되면 아래 화면이 나타난다.
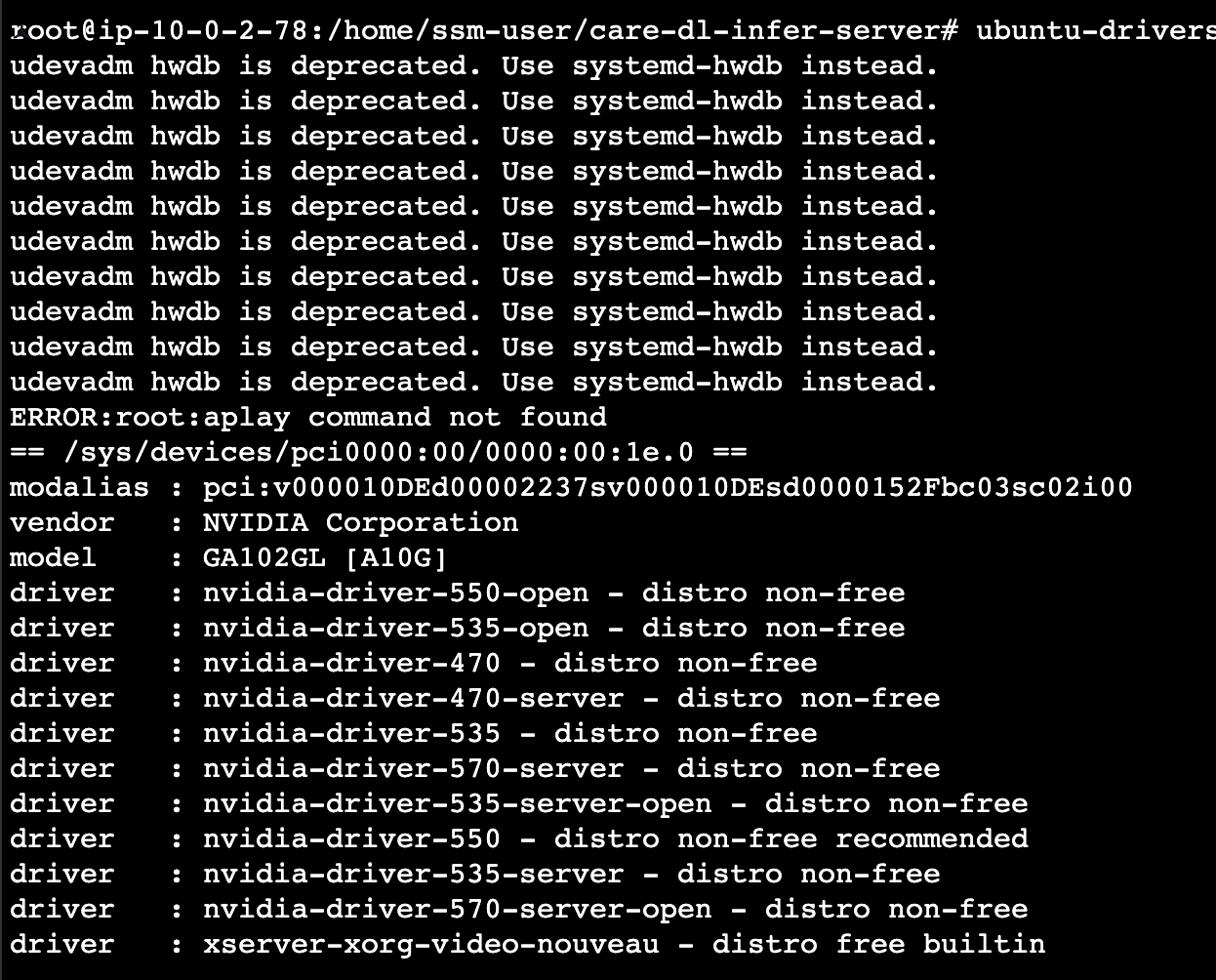
여기서 그냥 아무것도 모르고 driver 낮은 버전설치했다가 -> 호환이 안되서 시간만 엄청 잡아먹었다.
왠만하면 recommended 로 된걸로 설치하자 (2025.3.24일 기준 - nvidia-driver-550)
gpu driver 설치
sudo apt-get install nvidia-driver-550
sudo reboot ## 재부팅 후에 적용 완료 됨
nvidia-smi
오우 여기까지 나왔다면,
nvidia gpu가 설치가 된거다 (스크린샷은 470으로 찍힘)
Docker 내에서는 왜 안되지?
docker 서비스를 gpu 인스턴스에 띄워놓고, 테스트를 해보니... 추론모델이 cpu 만 사용하였다.

아... 뭐가 문제지
알고보니, container내에서 gpu를 사용하기 위해선 자체적인 toolkit 을 설치해야 한다. (이걸 알아차리기까지 2시간 가까이 소요됨)
container toolkit 설치 (docker가 설치가 이미 되어있다는 가정)
# NVIDIA GPG 키와 리포지토리 추가
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# NVIDIA Container Toolkit 설치
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
docker run --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
## docker deamon을 재구성
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
docker run --gpus all nvidia/cuda:12.4.0-base-ubuntu22.04 nvidia-smi
과연 잘 구성이 되었을까?
docker info | grep Runtimes
docker exec -it [container-id] /bin/sh
nvidia-smi ## nvidia 사용현황이 나와야 함
Docker 에서도 GPU 활성되게 하기
자 그럼 Container 내에서, 잘 동작되는지 확인이 되었으니 명령어에 gpu를 사용한다고 명시해보자...
docker run 명령어에 gpu 옵션 추가
docker run --gpus all [이미지명] [명령어]
docker-compose 에 gpu 옵션 추가
version: '3.8'
services:
[추론모델]:
build:
context: .
dockerfile: Dockerfile
container_name: [추론모델]
ports:
- "8888:8888"
restart: unless-stopped
volumes:
- ./logs:/app/logs
environment:
- TZ=Asia/Seoul
deploy: ## 이 부분 부터 추가
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8888/ping"]
interval: 30s
timeout: 10s
retries: 3
start_period: 10s
서버상태를 보니 기존 3초정도 걸렸던 작업이 -> 0.2 ~ 0.5 초로 줄었다.
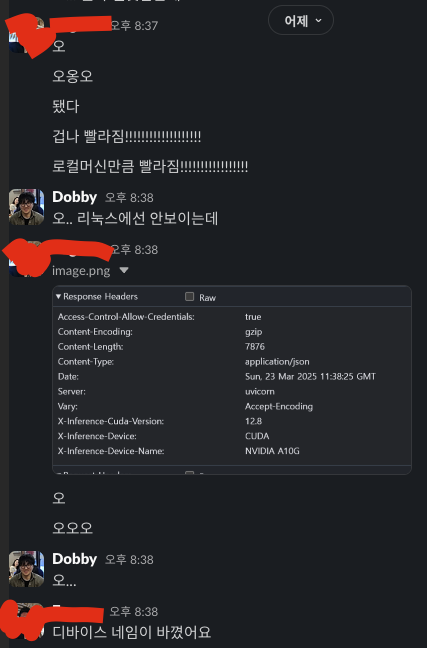
앞으로 해야할 일
- gpu 인스턴스를 EC2 로 구성하였다 -> AutoScaling, 모니터링, Disk 관련 부분들을 다시한번 점검해봐야 한다
- 현재 Service Code 모델로 인해 10~20GB 정도된다. 현재는 어쩔수 없이 S3로 주고받으나 다른방법을 모색해봐야 한다
- Github Submodule...
- Github Self hosted...
- CI/CD CD 구성은 아직 안했는데, main push 되면 ssm Run Command가 EC2에 명령을 질의하게끔 하면 되지 않을까?
나처럼 많이 헤멜것 같은 분들에게 한줄기 희망이 되길...
한 12번 포기할뻔 했는데 다행이 해냈다.
'Architecture > 회고 및 경험' 카테고리의 다른 글
| Database 권한제어 후기 (0) | 2025.04.03 |
|---|---|
| GPU 인스턴스 구성을 구성해보자 - 2 (0) | 2025.03.29 |
| Self Hosted -> CodeBuild (Gtihub Action) 로 넘어가기 (0) | 2025.03.16 |
| Platform Engineer의 대한 나의 생각 (0) | 2025.02.16 |
| Database Dump 방법 (0) | 2025.01.12 |