반응형
EKS + 당근페이 Case + BNX Case
Kuberentes
- 컨테이너화된 워크로드와 서비스를 자동적으로 배포, 스케일링 및 관리 ⇒ 오케스트레이션 도구
- 자동화된 롤아웃과 롤백
- Self Healing ⇒ Replicaset
- Service Discovery + Load Balancing
- Bin Packing ⇒ K8s가 알아서 CPU, Memory, 공간 알아서 해줌
- Secret 관리 및 구성 관리
EKS
- 인증된 k8s 버전
- 관리형 쿠버네티스 환경 구축/
Problems
- K8s 업그레이드를 자주 해야 한다 ⇒ 업그레이드 이슈
- Amazon EKS 업글은 3~4개월마다 업그레이드 할때마다 이슈
Amazon EKS 업그레이드 순서
- Master Node
- EKS master Upgrade
- CoreDNS Upgrade
- KubeProxy Upgrade
- Amazon VPC CNI Plugin Upgrade
- Worker Node
- 새 버전의 노드 그룹을 생성 → Pod를 이사시켜야 함…
Amazon EKS 업그레이드방법
- Single Cluter
- 기존 클러스터내에서, 한 version씩 업그레이드 (계단식)
- 1.15 → 1.16 → 1.17 → 1.18 각 버전당 40분씩 걸림 (Master Node) ⇒ 시간을 상당히 소요
- 잘 동작하고 있는 기존 시스템을 크게 변경하지 않음
- cordon, drain으로 무중단 업그레이드 가능 ⇒
롤백은 불가능
- 새로운 클러스터를 만들고, Traffic을 이전하는 방법
- Traffic을 새롭게 이전해야 하는데,
굉장히 어려움- ALB를
Terraform으로 수정해서 쉽게 바꿈 ⇒ALB + Terraform - NLB는
HA Proxy를 앞단에 두어 세밀한 설정을 가능하게 함 ⇒NLB + HA Proxy - 결국 트래픽전환이 잘 되었는지는, Prometheus, grafana를 사용해서 모니터링 해야 함…
- ALB를
- 업그레이드를 한번에 하니까 빠름 ⇒ 내부 시스템도 한번에 업그레이드 가능
- 트래픽 조절만 잘하면 무중단 업그레이드 가능
- 트래픽 조절만 잘하면 멀티 클러스터 운영도 가능
트래픽 조절⇒ Terraform + HA Proxy언제든 이전상태로 롤백가능Multi Cluster

당근마켓 인프라 구축 Case
Desc
- 당근페이 === FinTech
- FinTech Infra ⇒ 어려움
- 금융 서비스 라이센스 문서 작업 + 감독 규정 + Compliance
- 보안성과 업무 효율성의 기반한
망분리 100% 클라우드 환경에 구축
1. 로그인 시스템 구성
- 계정별로 환경이
분리- 개발 계정
- 운영 계정
- 로그인 할 수 있는
창구가 최소화로그인은 대표 계정 하나에서만…- Security 계정은 대표계정 ⇒ IAM만 존재
- 로그인을 할려면 무조건 Security 계정으로 들어와야 함
- 개발 / 운영 계정으로 Assume Role을 사용하여 넘어감
- 계정
탈취시, 여파를 최소화- 탈취 되어도 볼수 있는 정보가 없도록..
AWS Login Use Zero Trust Concept
- Security 계정
- EC2, RDS 이런 AWS Resource 아무것도 없음 ⇒
무조건 IAM⇒ 탈취해도 아무것도 못함 - Assume role을 사용해서 들어가야 함…
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": [ "arn:aws:iam::DEVAWSACCOUNTID:role/RoleNameInDevAccount", "arn:aws:iam::PRODAWSACCOUNTID:role/RoleNameInProdAccount" ] } ] }
- EC2, RDS 이런 AWS Resource 아무것도 없음 ⇒
- Dev / Prod 계정
- IAM 사용자가 없음
- 로그인 하는 경우는, Root 계정, Security → Assuming 형태로 들어갈 수 있음
2. 서버 접근
- 기본적인 서버 접근 방법은
- SSH
- Bastion Host + SSH 접근
- 약간 보완된 서버 접근방법
- AWS Session Manager
Teleport- Kubernetes 방식으로 운용 할 수 있음…
- Hashicorp Boundary
- Teleport (
약간 Cloud Trail과 비슷함)- 유료도 있으나, opensource로도 존재…
- RBAC 지원
- github.com 인증 연동
세션 레코딩 기능⇒ DataDog RUM과 같음- 로그인 한 사용자가, 어떤 행위를 했는지 다 보임 (지림)
- 물론, 기본적인 linux history나 그런게 있지만 시각적으로 볼수있다는게 장점…
3. 애플리케이션 접근
- Kubernetes vs EC2
- Kubernetes 너무 어려움… ⇒ hot한 이유가 있지 않을까?
- EC2 너무 쉬움…
- EKS Architecture in 당근페이
- ALB는 모두 Kubernetes Ingress
- 마이크로 서비스 간 호출은 ALB를 통해 호출
- 더욱 더 많은 Pod 내의 통신을 위해서
Istio를 고려를 하고있음

4. 배포 파이프라인
- Jenkins, TeamCity, Github Action 너무 좋은게 많지만,
- EKS는 왠만하면
ArgoCD, Github Action, ArgoWorkflow⇒ Github 과의 연동이 쉽고 간단함 - 배포 파이프라인
- 소스 코드 업로드 및 PR 생성 (
Github On-Premise사용)- EC2 자체의 대한 비용 (
m5.4xlarge로 하였음) - EC2 Disk의 종속이 있음
- EC2 자체의 대한 비용 (
- Github Action WorkFlow 동작 (Github Action)
- Github Action) ECR 업로드
- Kubernetes 매니패스트 Tag 업데이트
- Kubernetes 매티패스트 Tag 업데이트가 된걸 ArgoCD가 Check
- ArgoCD가 변경된 매니페스트를 EKS에 적용
- 소스 코드 업로드 및 PR 생성 (
- 해당 배포 파이프라인에서 사람손을 타는건 1~2 밖에 없음
- Github Action WorkFlow도 나쁘지는 않음 → 근데… Jenkins랑 별반다를거 없지만
- Github / Gitlab + Jenkins (
EC2 2EA) - Github (github Action) (
EC2 1EA)
- Github / Gitlab + Jenkins (
5. 관측 시스템
- DataDog (SASS)
- Elastic Stack (직접 설치)
- New Relic (SASS)
- Elastic APM (직접 설치)
- Prometheus (직접 설치)
- 원래라면 DataDog, New Relic을 사용하는것이 좋다 ⇒ 물론 비쌈
- 당근페이같은 경우에는, Compliance로 인하여 직접구축을 함
로그 시스템

Elastic Stack(로그 수집 및 시각화)Prometheus( 시스템 로그 수집)- WorkNode에는 DeamonSet (FileBeat + Node Exporter)로 구축
- Node Exporter 외에 여러가지가 존재…
- FileBeat + LogStash + ElasticSearch + Kibana
여기서 중요한 건, Elastic Search를 제외하곤 모두 EKS로 구현- Prometheus를 EKS로 구성하기 위해선?
prometheus-operator- 어떤 버전으로, 볼륨 구성의 관한것을 yaml 파일로 정의
APM 시스템

- Pod들 별로 APM Agent 별로 설치
- Elastic Uptime을 사용하여, 각 서비스들의 Endpoint들의 대한 모니터링
AWS Resource Monitoring

- 원래라면 CloudWatch + SNS + Lambda + Slack를 사용하여 구축
- CloudWatch + SNS + AWS Chatbot + Slack설정
AWS Chatbot을 사용하면 좀더 편리하게 관리가 가능… Metric 이미지까지도 쉽게 전송이 가능함…
6. 성능 테스트
- 당근페이에서는 성능테스트를 굉장히 중요하게 생각함…. ⇒ 사실 중요하긴 함
- 성능테스트 도구
- apache benchmark (HTTP / HTTPS 단의 부하테스트)
- klocust (kubernetes 기반에 동작하는 오픈소스)
10분동안의 테스트를 통해 99 Percentile 응답시간이 100ms 이내일때의 최대 TPS- pod가 받아낼수 있는 최대 TPS
- 즉 100ms 가 넘어가는 TPS를 측정한다
- 우리는 얼마일까… 해볼껄…
- 100ms 넘어가는 시점에서 ⇒ “
우리의 pod는 N TPS이구나. 이시점에 알람을 걸어놓자…”
BNX Case (Traffic 대응)

- 갑작스럽게 발생하는 트래픽을 어떻게 대응할 것인가?
- Weverse의 ALB Request Count가 22:30 ~ 23:00 까지 2.72M 까지 올라감 ⇒
평상시 100배 - 평균 거의 없는 수준임…
서버운영 어떻게 해야하지?- 한 순간을 위해 서버를 여러개 놔야 하나? ⇒ 비용 문제
- Auto Scaling? ⇒ Auto Scaling을 쓰면 한 템포 느림 (
5~10분 정도의 시간이 걸림) ⇒ 앱 버벅 및 느려짐 ⇒터짐
사전에 증설되는 순간을 감지할 수는 없을까? ⇒ Event Driven AutoScaling
- 이벤트에 의해 동작하는 오토 스케일링
Predefined Event : 미리 정의되어 있는 이벤트 ( MD 판매 이벤트 )

- 특정 아티스트의 MD 판매 이벤트는 언제 팔지 알기때문에 → 사전대응가능
- 스케일링의 업무 수작업은 → 업무 효율이 떨어짐 → Lamba로 구성
- 이벤트 등록을 하고, Lambda는 몇분, 몇시간동안 계속
이벤트를 조회 - 조건에 맞는 이벤트를 찾는다면, AutoScaling의 값들을 수정해준다…
- Desired Count
- Max
- Min
- AutoScaling 한 결과를 Slack 채널에 결과를 전송
Undefined Event : 미리 정의되어 있지 않은 이벤트 ( 아티스트의 글 작성 )

- 아티스트가 글 작성은 사실 언제 작성이 될지 아무도 모름 ⇒ 사전 대응이 불가능
- Push는 GCP Cloud 같은 걸로 보낸다
- API Gateway를 호출한다 → Lambda 호출 물론, CloudWatch Cron을 사용해서 주기적으로 호출한다.
- Undefined의 종료조건은
- 글 작성 후 30분후에 Auto Scaling을 원상복구
해결해야 할 과제… (아직 해결해야할 과제들이 많이 남아있음)
1. AutoScaling에 소요되는 시간의 최소화
-
- ansible을 사용하여 Linux → 공통 설정 → FileBeat 설정 → API Server 구동 (
전체 과정이 5분 소요) - 이게 AutoScaling을 하게되면 이러한 과정이
5분동안 진행된다는 관점이라면,ECS + Step Scaling을 하는게 더 빠르겠네 (1~2분 이내의 증설)(METAPIXEL)- AMI를 미리 만들자.. (
Golden Image)
- 개선된 배포시스템
- 이렇게 해서 전체과정이 3분정도 소요… →
하지만 목표는 1분안에 증설 완료
- 이렇게 해서 전체과정이 3분정도 소요… →
배포 과정을 최적화
- ansible을 사용하여 Linux → 공통 설정 → FileBeat 설정 → API Server 구동 (

2. 증설되는 동안 최대한 버텨주기 (제발…) ***
인스턴스 성능 최적화- 잘 튜닝된 t3.medium,
10개 c5.xlarge 안 부럽다. - 성능최적화의 핵심은 모든 리소스를 최대한 활용하는 것
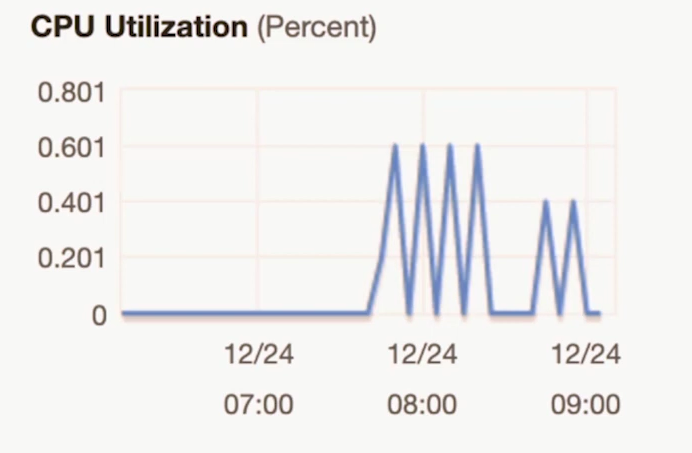
- 성능 튜닝 전 EC2 (장애상황)
- 리소스가 펑펑 남아돔에도 불구하고 CPU 1% 차지않고도 에러가 남…
- OS와 애플리케이션 디폴트 설정으로 애플리케이션 설정에 영향을 받지 않아야 한다.
- Too many open files
- Too many connections
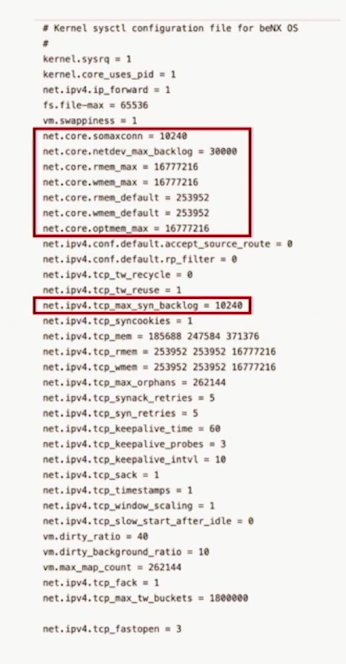
- 성능 튜닝 1
- Application 에서 더욱 많은 리소스를 요구할때, OS Limit을 Full로 쓰게 만든다.
- 성능 튜닝 2
Nginx 성능 튜닝- https://www.nginx.com/blog/tuning-nginx/
- nginx 성능 중 가장 중요한 지표
- c5.12xlarge를 데려와도 장애 납니다.
worker_processes도 실제 cpu core수만큼으로 돌려야 한다.worker_connection도 늘려줘야한다.- worker_connections는 결국 client 와 server간의 역할을 담당하기 때문에 양을 늘려줘야 한다.


반응형
'컨퍼런스 내용정리' 카테고리의 다른 글
| 강연정리) EKS 아키텍처 구성하기 (0) | 2024.12.22 |
|---|---|
| 강연정리) EKS + Kinesis = CQRS (1) | 2024.12.22 |
| 강연정리) 대규모 마이그레이션 전략 (0) | 2024.12.22 |
| 강연정리) 글로벌 채팅 서비스 (카카오) (1) | 2024.12.22 |
| 강연정리) 굿닥 AWS EKS 전환사례 (0) | 2024.12.22 |