반응형
굿닥 AWS 전환사례
굿닥의 Pain Point
- 사내 서버 운영 관점에서 → 장애 상황에 대한 대응이 어려움
- 비즈니스 요구사항에 맞춰서 개발하다보니 →
언어 5개, 서버 1000+a, db 30+a - 5000여개의 병원 클라이언트에게 보장가능한
신뢰성이 떨어질 염려가 있음 - 예측할 수 없는
트래픽 급등의 대해서 대처가 좀 힘들었음- 월 200(MAU)
- 코로나로인한 비정기적인 트래픽급증의 준비가 미흡했음
어떻게 수정했어야 했나?
Container- 언어 및 Framework에 종속적이지 않음
- Runtime 시점에만 Container가 구동됨
- 만약? Container가 아주 많아지게 된다면?

- 규모가 커질수록 Container Cluster 환경을 구성하기에는 어렵다.
- Container 자체를 어떤 인스턴스에? 어떤 전략으로? 배치하는 방법이 필요하다.
- 시스템의 모든 상태를 알아야 한다.AWS Container Orchestration
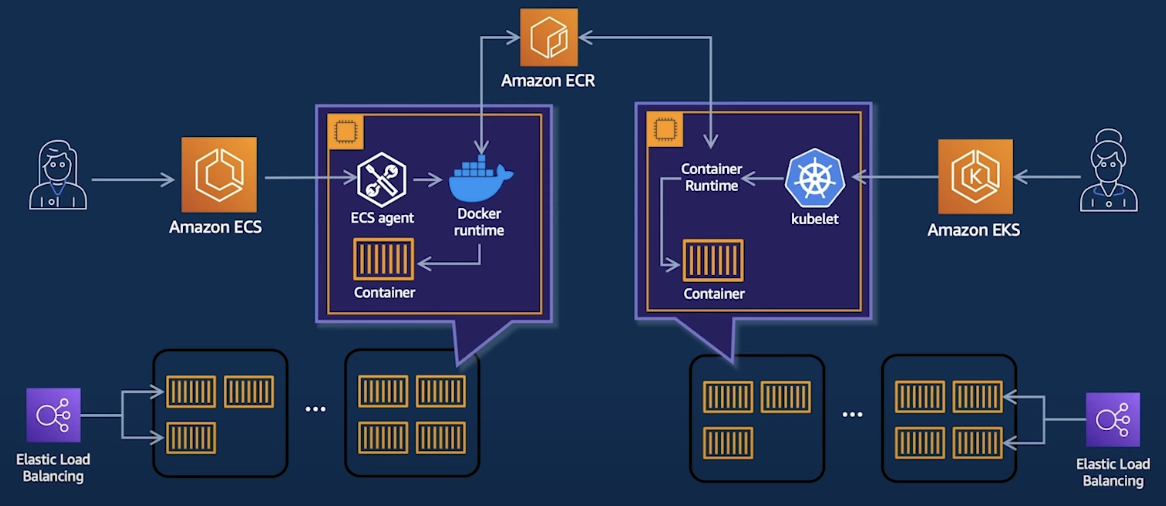
- 두 서비스의 공통점
- Control plane을 AWS에서 직접 관리한다
- Data Plane 모두 AWS에서 관리하기 때문에, 편하게 인프라를 관리한다
- image Registry는 Docker hub / ECR을 사용한다.
ECS- control-plane :
ecs-agent
- control-plane :
EKS(굿닥은 이걸 사용함)- control-plane :
kubelet - open source의 kubernets를 관리하지않는다 →
직접 구성 X - aws는 4개의 kubernetes minor 버전을 지원 →
upgrade 버전까지 시간을 충분히 줌 - control-plane의 보안, 확장성을 제공 →
가장 어려움
- control-plane :
굿닥 + EKS 여정
- 배포, 모니터링, Convention 등 여러 언어와 프레임워크를 대응하기에는 어려웠음
Service Oriendted Architecture (2022)⇒ 개별 서비스에 집중하는 아키텍처 스타일- 재사용 가능한 모듈을 서비스 별로 만들어서 → 비즈니스에 맞게 → 서비스 모듈을 키워나감
- 1개의 DB, 1개의 언어, 1개의 Framework로 통일을 진행
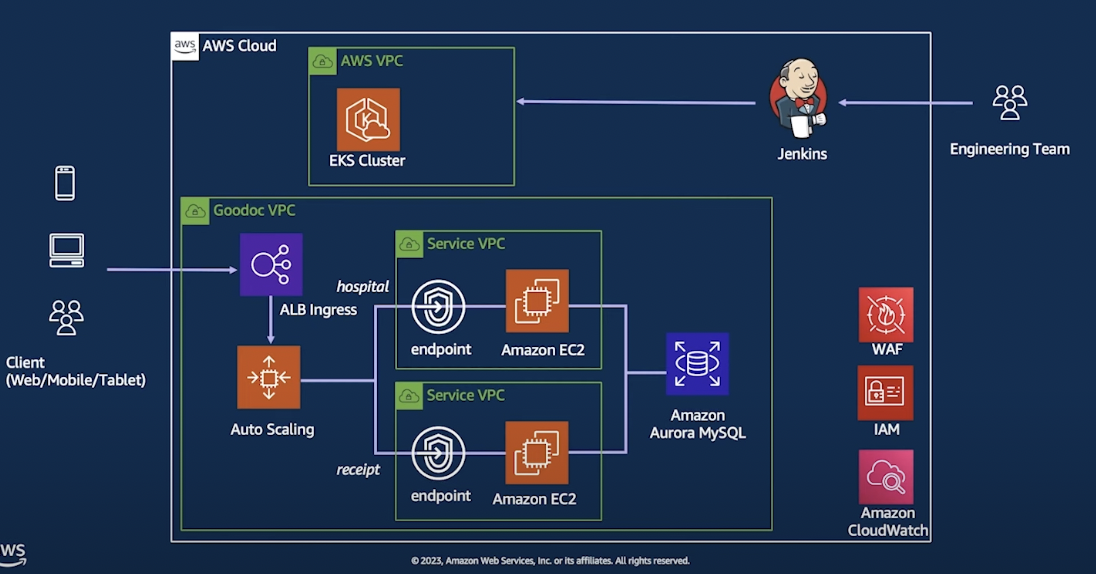
- 동작방식
- ALB Ingress에서 트래픽 분산
- Auto Scaling을 통해서 Container 수 조절 → 처리
- EKS Cluster → Container Orchestraion을 처리
- 각각의 Endpoint에서 해당 로직을 처리
- Database (Amazon Aurora MYSQL) 복구 기능 추가
- 이를 통해 얻은점
- 관리 리소스 절감 → 파편화 되었던 리소스를 줄였음
- 모니터링이 더 수월함
- Convention 통일을 통해서 복잡성 감소
- 한계점
- 배포 주기가 길어짐
- 하나의 DB에서 모든 서버가 의존
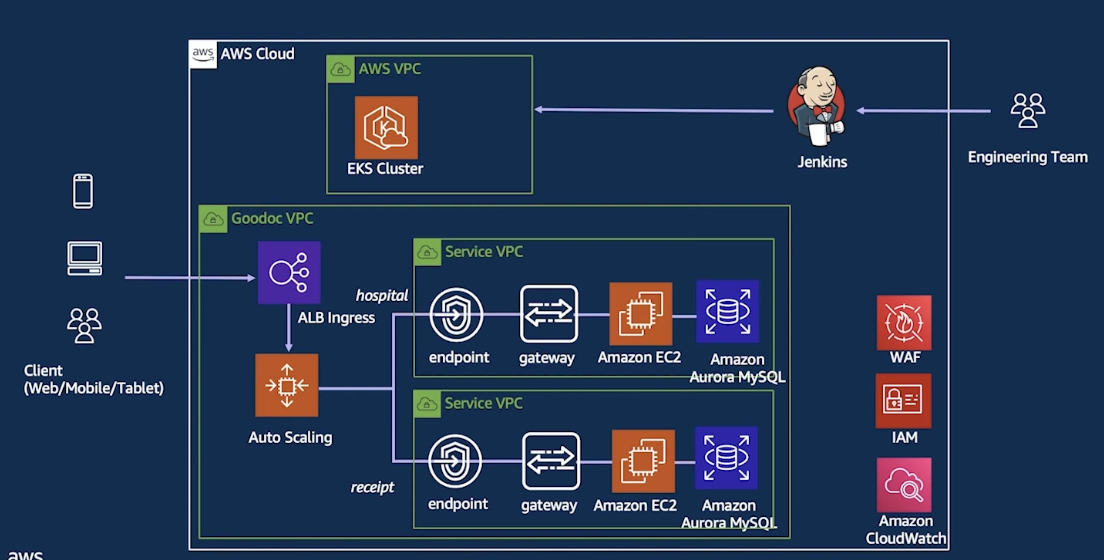
- Micro Service Architecture (2023) → 마이크로 서비스 도입
- 하나의 Context안에 Service + DB를 묶어준 후 → Gateway로 통신
- 각각의 서비스는 독립적으로 운용 + 배포 ⇒ Agility를 높일 수 있음
- 각각의 서버와 DB를 운영하기 때문에 →
각각의 팀이 존재 - endpoint 와 ec2 안에 gateway만 생김
AWS Data Lake 구축하기
어떻게 적재할 것인가?
- 각각의 데이터가 Bronze Data로 Ingestion 되기 위해선 format이 다 다르다.
- 각각원하는 형태가 있고 로그형태가 다르다..

- S3로 적재한다
- AWS내의 Data Engineering은 S3에서 시작해서 S3에서 끝난다고 할 수 있다.
Athena를 통해서 SQL 질의도 가능하다QuickSight를 통해서 의사결정의 대한 BI를 구축할 수 있다.
Easy DataLake Architecture

- 고객행동로그 →
WebServer - Transaction Data →
Database - 유저 행동로그 →
GA - 외부 데이터 →
Google Spread Sheet
S3 + Glue Cralwer + Athena
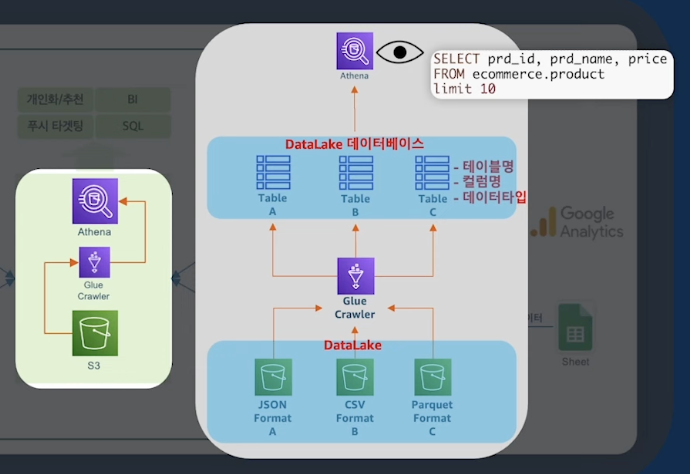
- S3 → Glue → Athena
- S3 서비스를 통해서 만든 저장소 (
Data Lake) - Athena는 Serverless Query Service
- S3 데이터가 많기때문에
Partitioning이 되야한다.
Webserver Pipeline
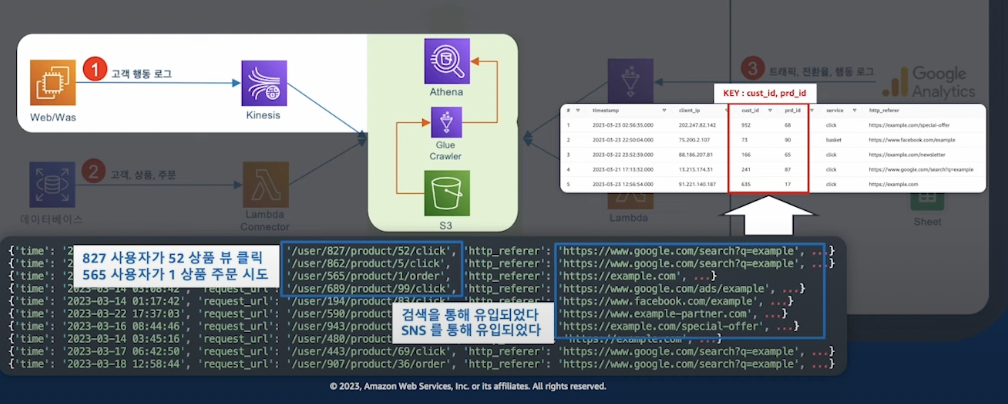
- WebServer는 Kinesis Firehoes를 사용하여 Data Pipeline을 구축할 수 있다.
- 대용량의 트래픽이 발생할 경우 Kiensis Firehoes 만으로는 힘듬 (
Buffer가 있으나 대용량은 벅참+ Kinesis Data Stream 함께 써야 함) - Kinesis Firehoes를 사용해서, Data Format도 가능하다.
- Webserver에서는
Kinesis Agent를 설치할 수 있음 - Kinesis 에이전트를 사용하여 Kinesis Data Firehose에 쓰기 - Amazon Kinesis Data Firehose
- Kinesis DataStream Shard 2개면 왠만한 양은 버틸 수 있음
- 하루 25,000,000 양의 데이터
- Kinesis DataStream shard * 2
- Kinesis Firehoes
200$ 남짓
Database Pipeline
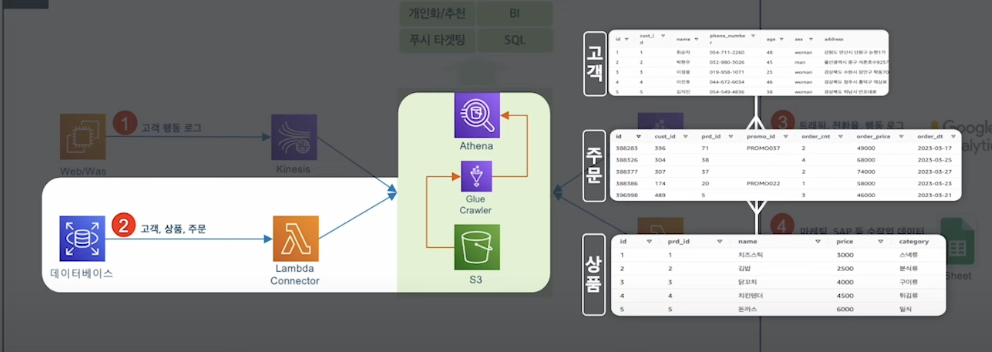
- 고객의 OLTP 데이터를 수집하는 방법
- DB Data Pipeline Architecture는 여러가지 방법이 존재
- (실시간) DML 관련된 데이터를 수집하기 위해서는 →
AWS DMS + Hudi or Iceberg - (배치) AWS Glue Job을 사용해서 하루 1회 Batch 할 수 있음
- 실시간에 가까워질수록
운영이 어려움
- (실시간) DML 관련된 데이터를 수집하기 위해서는 →
- 빠르게 분석환경을 도입하기 위해선
Lambda Connector를 사용한다면, Direct로 DB데이터를 조회 가능 - 만약, DB 데이터가 대용량이라면 부하가 발생할 여지가 존재 →
대용량이면 이러한 architecture는 별로임.. - Lambda Connector는 Athena 서비스를 통해서 만들 수 있음
GA Pipeline
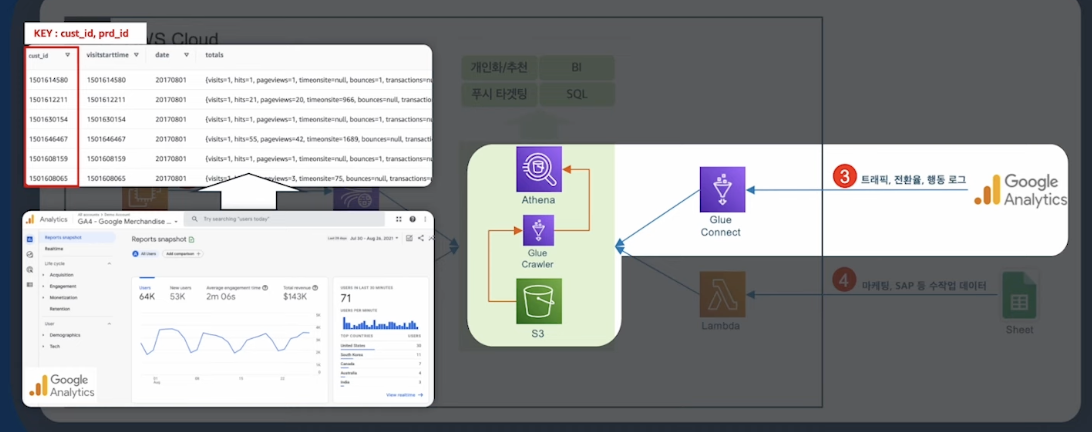
GA는 행동기반 로그에 가깝다- 실질적인 데이터를 얻기 위해서는 OLTP 데이터랑 합쳐서 봐야한다.
- AWS Glue Connect는 다양한 소스와 연결이 가능하다.
- Bigquery에서에 데이터를 S3 데이터로 옮겨올수 있다.
BI (데이터 시각화)
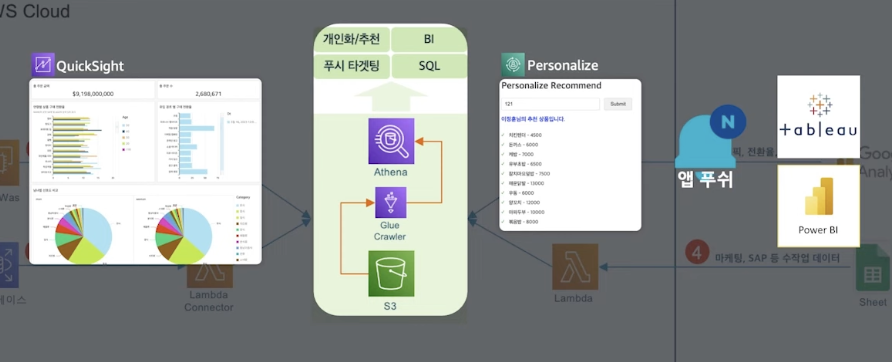
- QuickSight
- Personalize
반응형
'컨퍼런스 내용정리' 카테고리의 다른 글
| 강연정리) EKS 아키텍처 구성하기 (0) | 2024.12.22 |
|---|---|
| 강연정리) EKS + Kinesis = CQRS (1) | 2024.12.22 |
| 강연정리) 대규모 마이그레이션 전략 (0) | 2024.12.22 |
| 강연정리) 글로벌 채팅 서비스 (카카오) (1) | 2024.12.22 |
| 강연정리) EKS + 당근페이 + BNX (0) | 2024.12.22 |