반응형
개요
- EKS Version Rolling Upgrade
- Addons Update
- Control Plane / Data Plan Update
요구사항
- EKS 1.33 -> 1.34 (Control Plane Update)
- 기본적으로 제공되는 Managed Addons Update
- 설치한 Addons들 업데이트
- Data Plane Update (Rolling ...)
- 이때 Data Plane은 Self hosted 로 테스트 진행
Self hosted Node Group 생성
- Managed NodeGroup으로 안한이유는... 회사환경과 맞추기위함
- node group 생성
- eksctl create nodegroup -f test-ng.yaml (System node)
- eksctl create nodegroup -f app-ng.yaml (App node)
# test-nodegroup.yaml
# eksctl create nodegroup -f test-ng.yaml
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: hub
region: ap-northeast-2
managedNodeGroups: [] # 기존 managed는 건드리지 않음
vpc:
id: vpc-id
securityGroup: sg-id
subnets:
private:
ap-northeast-2a: { id: subnet-id }
ap-northeast-2b: { id: subnet-id }
ap-northeast-2c: { id: subnet-id }
nodeGroups:
- name: test-upgrade-ng
instanceType: t4g.small
desiredCapacity: 2
minSize: 1
maxSize: 3
privateNetworking: true
amiFamily: AmazonLinux2023
labels:
role: test
version: "1.33"
node.kubernetes.io/role: "system"
node-type: "system"
tags:
Environment: test
k8s.io/cluster-autoscaler/hub: "owned"
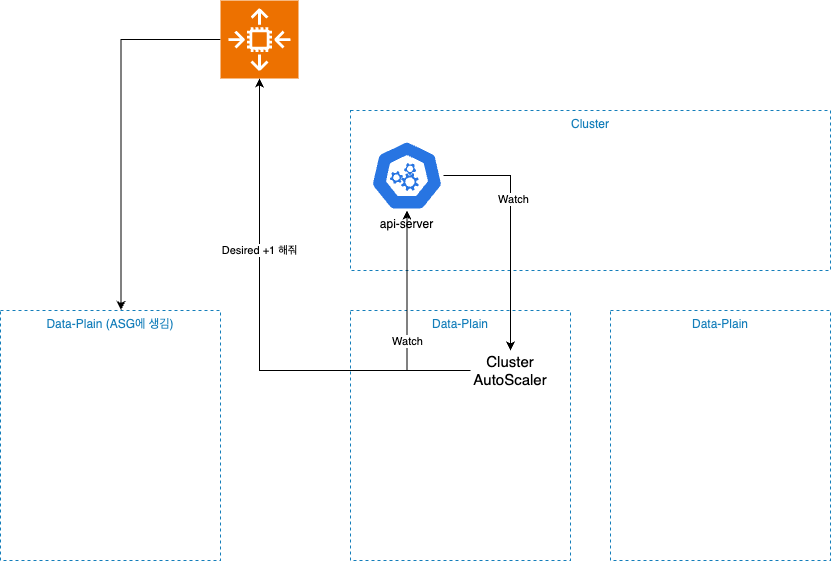
k8s.io/cluster-autoscaler/enabled: "true"- 2개의 Self hosted Node Group은 Cluster AutoScaler 로 구성
exteraArgs:
scale-down-unneeded-time: 10m
scale-down-utilization-threshold: 0.4
nodeSelector:
role: test
1.33 -> 1.34 로 업그레이드 (Rolling Upgrade)
Core Addons 들의 Version 확인
- VPC CNI (v1.21.1-eksbuild.1)
- CoreDNS (v.13.1-eksbuild.1)
- Kube-Proxy(v.1.34.1-eksbuild.2)
aws eks describe-addon-versions \
--kubernetes-version 1.34 \
--addon-name coredns \
--query 'addons[0].addonVersions[0].addonVersion' \
--output text
aws eks describe-addon-versions \
--kubernetes-version 1.34 \
--addon-name kube-proxy \
--query 'addons[0].addonVersions[0].addonVersion' \
--output text
aws eks describe-addon-versions \
--kubernetes-version 1.34 \
--addon-name vpc-cni \
--query 'addons[0].addonVersions[0].addonVersion' \
--output text
자체적으로 설치한 Addons 들의 1.34 호환 버전을 찾아보자
- 이건 직접 발품찾아야 함 -> 대부분 신규 버전이라면 호환됨...
- external-dns
- load-balacner-controller
- cluster-autoscaler
Managed Node Group (Self hosted) 는 Instance refresh를 사용해서 Upgrade
- 이때, 주의할건 업그레이드 시점에서 Cluster AutoScaler로 인해 ScaleIn 이 될수있기때문에 미리 Replica를 0으로 줄여놓자...
## https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/charts/cluster-autoscaler/values.yaml
replicaCount: 0
exteraArgs:
scale-down-unneeded-time: 10m
scale-down-utilization-threshold: 0.4
nodeSelector:
role: test
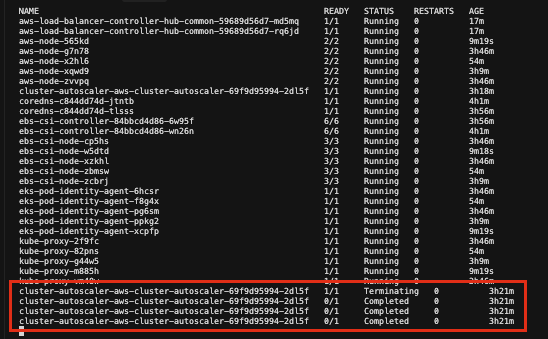
좋아... Rolling Upgrade Let's go
0. Cluser AutoScaler 0 으로 줄이자... (위에 기재함)
1. Control Plane Upgrade (1.33 -> 1.34) + Core Addons Upgrade
- Terraform 으로 1.34 로 올리면, 다른 Core Addons 들도 같이 올라가는것으로 보인다...
- Control Plane은 10분가량 걸림 (terarform 설정을 봐야겠지만, addons들은 버전이 안바뀌었음 -> 수동으로 설정)
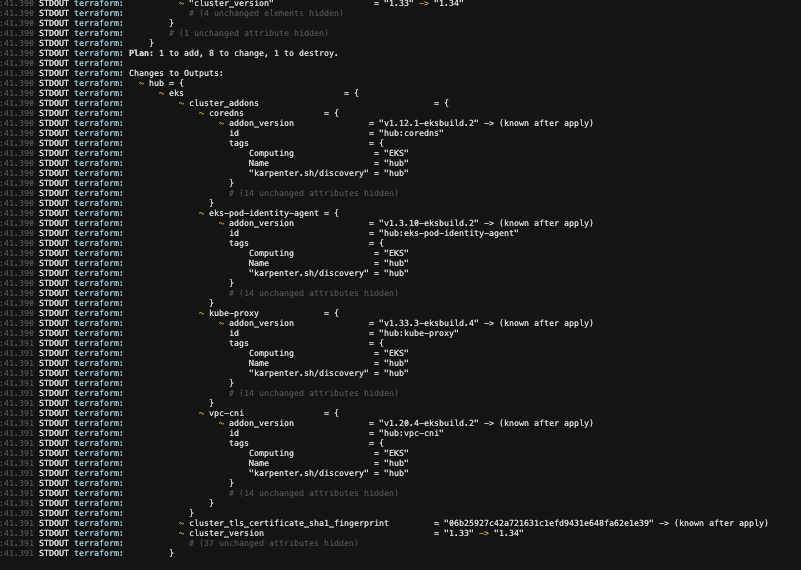


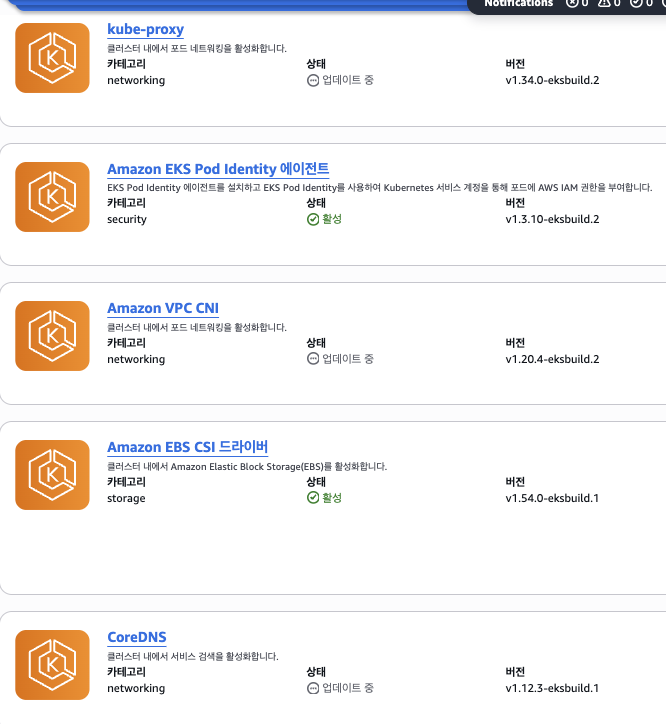
2. Managed Addons Upgrade (없으면 생략)
- 이건생략 함
3. Data Plane Upgrade (Restart)
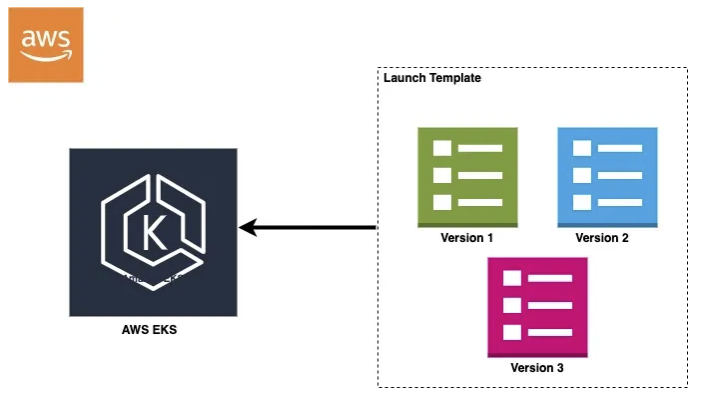
- Launch Template 수정 (1.34 AMI 에 맞게)
## x86
aws ssm get-parameter \
--name /aws/service/eks/optimized-ami/1.34/amazon-linux-2023/x86_64/standard/recommended/image_id \
--region ap-northeast-2 \
--query 'Parameter.Value' \
--output text
## arm
aws ssm get-parameter \
--name /aws/service/eks/optimized-ami/1.34/amazon-linux-2023/arm64/standard/recommended/image_id \
--region ap-northeast-2 \
--query 'Parameter.Value' \
--output text
## LT 수정
aws ec2 create-launch-template-version \
--launch-template-id lt-xxxxx \
--source-version '$Latest' \
--launch-template-data "{\"ImageId\":\"$AMI_ID\"}" \
--region ap-northeast-2
- 기존 인스턴스의 용량을 2배로 증설하고, 추가된 인스턴서의 ScaleIn Protection 후 기존 Desired Count를 기존용량으로 줄인다
- 이때 위험한 워크로드라면, 1개씩줄이자...

- 이슈가 없는지 잘 모니터링 하자...
kubectl get events --all-namespaces --watch --sort-by='.lastTimestamp'
FailedToUpdateEndpointSlices <- 이런 에러가 가끔 나지만, 노드 삭제중 일시적으로 발생하는 에러임 ( Pod 스케쥴링으로 자동 해결 됨)
반응형
'Architecture > K8S' 카테고리의 다른 글
| k8s AutoScaling 동작구조 비교 (0) | 2025.06.21 |
|---|---|
| K8S - 시작 ( 용량산정 / 고려사항 ) (2) | 2025.06.02 |
| K8s - Karpenter (2) | 2025.06.01 |