개요
테라폼에 대한 나의 견해
효율적인 Terraform Architecture
Terraform을 효율적으로 사용하는 방법 (나만의 생각)
테라폼에 대한 나의 견해
Terraform은 만능이다? 테라폼이 만능은 아니다.
테라폼 외 여러가지 IaC 툴이 존재한다. 나도 모든 툴을 깊게 사용해본것은 아니지만 몇몇 프로젝트에서 사용해봤다.
여러가지 툴을 사용해보면서 경험해본 결과 그나마 테라폼이 내가 생각했던 모든 부분을 충족하는 것 같다.
사용해본 결과는 아래와 같다.
구문을 이해하기 쉬운가?
헙업하기 쉬운가?
Code Standard 규칙이 Strict 한가?
개발하기 편한가? (멱등성, Plan, State)
CloudFormation
X
X
O
X
AWS CDK
O
O
O
X
aws-sdk 활용
X
X
X
O
Terraform
O
O
O
O
어쩌면 Terraform 편파적일 수는 있지만 이유는 이렇다.
Assembly급의 CloudFormation 내가 생각했을때는 CloudFormation은 IaC 중 Assembly 급인것같다.
알아보기도 쉽지않고, yaml 코드 인것같기도 하고 뭔가 코드 문맥을 이해하기도 어렵다 (물론, 계속 보고있으면... 쉬울지도)
기본적으로 CloudFormation 내 규칙이 완벽하게 존재하지만, 협업하거나 긴 구문을 이해하는것은 특히나 너무 어렵다.
CloudFormation
자유롭고 쉬운만큼 개발의존성이 높은 AWS CDK AWS CDK는 정말 좋은 Tool 이라고 생각한다.
물론 AWS CDK 는 CloudFormation을 한번더 추상화한 모델이고 이를 좀더 편하게 사용하기 위한 방법을 제공한다
하지만 보통 이런 툴 자체는 근본적인 문제가 존재한다. 보통의 개발자 / 회사라면 자체내에서 사용하는 언어 및 Standard Rule이 존재하게된다.
그러한 규칙을 하나하나 지키면서 AWS CDK를 사용하는 순간, 좀더 어려워지고 관리하기가 버거워진다.
인프라가 올라가면 개발 난이도도 올라가는것처럼 변하게 된다. 물론 이 부분도 효율적으로 코드리뷰 하면서 관리하면 좋지만....
실제로 개발하다보면 지켜지지 못하고 그렇게 된다면 레거시가 되는건 금방이다...
AWS CDK
변태들을 위한 AWS-SDK 라이브러리를 위한 인프라 구성 여긴... 솔직히 변태적인 부분이긴 하지만 몇몇회사에서는 AWS-SDK 라이브러리를 활용해서 한다고 들었다.
뭐 어떻게 구성하냐에 따라 더 효율적인 부분도 있겠지만 굳이... 일까 쉽다.
물론 AWS-SDK 도 CDK 처럼 Code Standard 문제가 있을 수 있다. 어쩌면 CDK 보다 더 빡셀수도 있겠다.
AWS SDK
테라폼은 만능이다2 ? 물론, 테라폼도 여러 단점들도 존재한다.
테라폼 언어를 배워야 하며...
테라폼 특유의 syntax를 이해해야 하며...
state 관리 및 provider에 골머리를 앓을 수 있으며...
에러가 날때, 가끔 잘 안알려줄 수 있다는...
4가지 외 여러가지 단점이 존재할 수는 있지만, Devops Engineer 입장에서 사용 및 회사 인원들과 협업하기에는 좋은 언어라고 생각한다.
내가 생각한 장점은 아래와 같다
테라폼 특유의 규칙이 존재 -> 해당 규칙만 따르면 됨
state 관리할 수 있음 -> 버저닝형태로 관리할 수 있으며, 인프가 구성실수에 있어서 빠르게 대처할 수 있음
인프라 Provisioning 이 다른 tool 보다 빠르다 -> 구체적인 실행속도는 추후 비교해볼수 있으나, 기본적으로 빠름
테라폼에 친화적인 Open Source가 많음
결론적으로...
테라폼이 IaC Tool 중 만능은 아니지만, 위에 기재된 이유로 개인 / 회사에서 쓰기에는 제일 적합한 도구라고 생각한다
( 물론, 다른 도구도 어떻게 쓰이냐에 따라 다를 수 있음 )
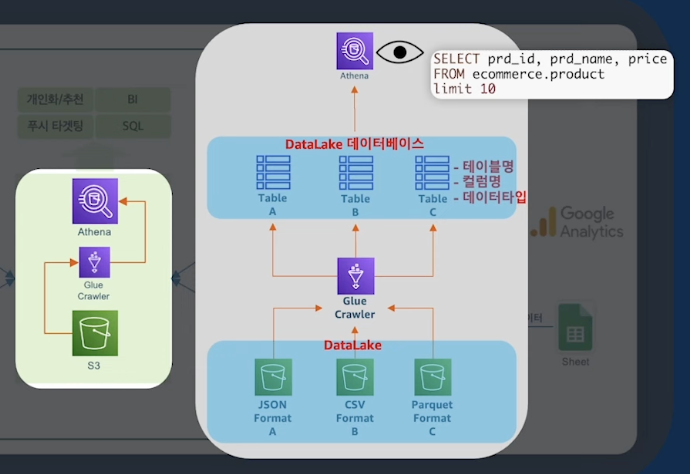
효율적인 Terraform Architecture
로컬에서 Cloud로... 보통 테라폼 언어와 명령어를 익히면 로컬에서 대부분 작업을 하게 된다.
이때 provider를 기재하는 여러가지 방법이 존재한다.
Profile을 활용
Access / Secret Key 활용
이렇듯 하다보면 .tfstate 파일은 로컬에 남게된다.
tfstate 파일에 대해서는 깊게 설명하지는 않겠지만 현재 인프라에 상태를 기록하는 파일이다.
만약, 이런 파일이 없어지게 된다면? -> 생각만 해도 악몽이다.
그렇기 때문에 tfstate 파일을 cloud에 올려서 관리하게 된다.
S3 Backend 코드
Backend Block에 S3 Path에 state 파일을 기재해서 관리한다.
물론 동시성 문제로 Lock 옵션에 대해 DynamoDB 를 추가할 수도 있고,
S3 대신 Terraform Cloud 아니면 Atlantis 를 사용할 수도 있다. ( OpenSource는 나중에 쓰는걸로... )
�협업을 어떻게 효율적으로 구성할 것인가?
이제 State 문제도 해결되었고, 보통에 3~4명에 협업을 하는 구조라면 IaC 코드를 Git 같은 VCS로 관리하게 될것이다.
VCS로 관리를 하면서도 여러가지 문제가 발생할 수 있다.
왜냐면 아직 state 파일 자체는 S3를 사용하지만 테라폼 실행은 본인이 하기 때문이다.
내가 아주 좋아하는 명언이 있다. ( 좀 딕션이 강하지만.... 의미만 )
휴먼이슈의 대한 고민
휴먼이슈는 어딜가나 생긴다.
그럼 협업 포인트에 앞서 이 휴먼이슈를 어떻게 줄여야 할까?
내가 찾은 답은 Terraform Cloud를 활용하여 Plan / Apply 및 프로젝트에 대한 권한을 나눌 필요가 있다고 생각하였다.
( 물론 이 문제를 고려하는 집단이라면, 어느정도 인프라가 규모가 있다는 전제하임 ... )
terraform cloud를 활용한 인프라 구성
테라폼 클라우드를 사용함으로써 아래와 같은 문제가 해결된다.
private variables 관리
state 를 s3 -> terraform cloud 로도 관리할 수 있음
terraform 실행에 대한 관리 전담
각 workspace / task 별로 브랜치 및 tag 배포와같은 협업 규칙 확립 가능
뭔가 좀더 나이스 해지지 않나?
물론 Terraform cloud는 부분유료 서비스다. 유료로 사용한다면... 정말 많은 기능을 사용할 수 있지만
우리회사도 아직은 Standard 로 사용하고 있다. ( 만약 회사 관계자 분들이라면 Plus 계약하라는 MSP 분들에 상술에 당하지 않도록...)
모듈화 의 대한 고민 Terraform Free / Standard Plan으로도 위에 장점을 어느정도 활용할 수 있다.
그럼이제 고도화된 문제의 대해서 한번 고민을 해볼 차례이다.
인프라 구성시 좀더 효율적으로 빠르게 만들수는 없을까?
공통된 정책에 따라서 인프라를 구성할 수는 없을까?
테라폼으로 몇몇 부분의 작업들을 효율적으로 구성했지만, 이제는 그로인한 피로 포인트를 줄여야할 때이다.
해답은 Module 이다
모듈을 어떻게 구성하고 활용하냐에 글은 정말 많고 다양하다.
하지만 내가 생각하는 모듈화의 규칙은 아래와 같다.
모듈은 의존성은 최소한으로 기재한다
모듈을 구성할때 README.md 정도는 어느정도 자세하게 기재하자
모듈을 사용하는 사람입장에서 생각하자
위 3가지 포인트를 어느정도 쉽게 설명을 해보자면...
모듈은 의존성은 최소한으로 기재한다
보통 모듈을 만들다 보면, 모든 리소스를 다 때려박는 더러 존재한다.
예를들면, Computing 모듈을 만든다고 했을때 VPC, EC2, SG, ALB 한번에 끝내려고 한다.
물론 이렇게 해놓으면 편하지만...
개발 및 구성을 하다보면 여러가지 문제에 직면한다
세부구성을 바꿔야 한다던지, 모듈중 필요없는 리소스를 지워야 한다던지
그때마다 모듈의 코드를 수정하고 기재하다보면 아래과 같이 고통이 늘어간다...
버전증가 악몽
정답은 없지만,
현재 본인 / 회사의 인프라 구성을 파악한 후, 뭔가 계속적으로 바뀌는 부분과 Static 하게 남아있는 부분을 인지하고
서로의 의존성을 최소한으로 구성할 수 있도록 확인해야 한다.
모듈을 구성할때는 README.md 정도는 어느정도 자세하게 기록하자
나는 테라폼을 잘 사용한다고 생각한다.
회사에서 모듈도 내가 만들고, 팀원분들께 모듈에 대해서 리뷰하고 사용한다.
근데... 내가 놓친 것이 하나있었다
팀원분들도 테라폼을 잘 사용하다고 생각하면 안된다는 것이다.
개인 역량일수도 있고, 공부하기 귀찮을 수도 있고, 그냥 어려울수도 있고 여러가지 이유들로 테라폼의 활용능력은 천차만별이다.
그럼 테라폼도 잘 사용하지 못하는 사람에게 terraform module을 리뷰한들, 소귀에 경읽기 일 것이다.
그렇다면 잘 사용하길 바란다는 마음으로 README.md 라도 잘 작성하는 예쁜 마음을 지녀보자...
다행히 테라폼에서는 terraform docs을 제공한다.
## terraform-docs 설치
brew install terraform-docs
## 현재의 모듈이 있는곳에서 진행
terraform-docs markdown table \
--output-file README.md \
--output-mode inject \
.
모듈을 사용하는 사람입장에서 생각하자
사실 이 부분은 내가 제일 중요하게 생각한다.
보통 Backend 개발을 했었던 사람이라면 아래와 같은 그림에 대해서 익숙할 것이다.
개발론적인 얘기를 조금 한다면,
보통 Contoller Layer 에서 Repository Layer로 갈수록 비즈니스 로직을 수반하게 되고, 그럴수록 점점
코드나 로직이 구체화되게 된다.
이런 구조에서 Controller / Service Layer 내에서는 구체화된 메서드를 활용함에 있어서 이슈가 없어야 한다는 얘기다
그래서 뭐... 대학생때 Solid 원칙이니... 고차함수를 이용해서 파라미터 전달하거나.. 뭐 여러가지 배우는데
테라폼을 사용할때도 똑같다고 생각한다.
테라폼 모듈은 어떻게 보면 비즈니스 모델이라고 생각한다면...
그걸 사용하는 사람은 해당 모듈을 사용함에 있어서 큰 문제가 없어야 한다.
참고 (Terraform module)
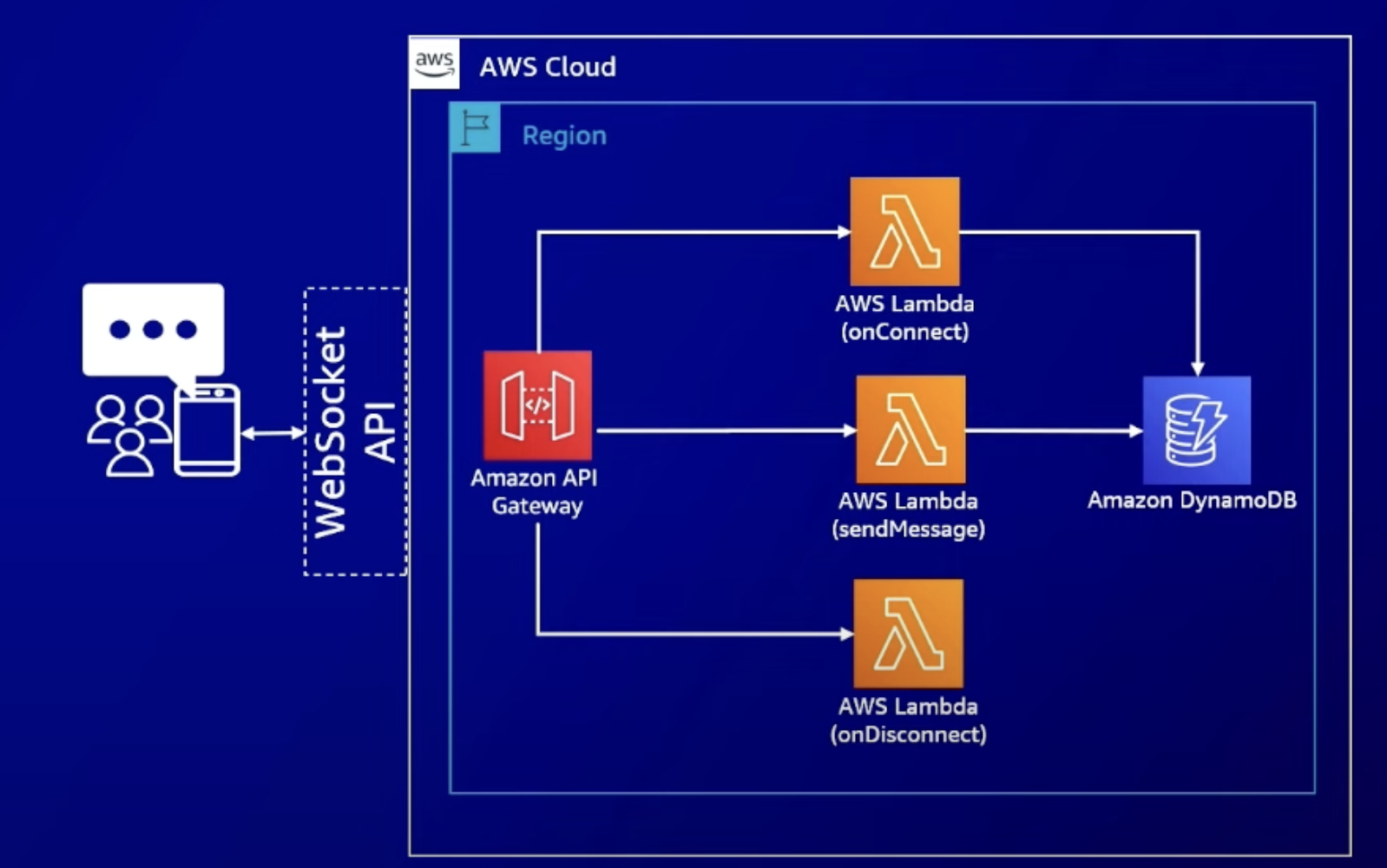
https://github.com/zkfmapf123/terraform-donggyu-lambda
GitHub - zkfmapf123/terraform-donggyu-lambda: terraform lambda template
terraform lambda template. Contribute to zkfmapf123/terraform-donggyu-lambda development by creating an account on GitHub.
github.com
https://github.com/zkfmapf123/terraform-donggyu-ecs-fargate
GitHub - zkfmapf123/terraform-donggyu-ecs-fargate: ecs-fargate module
ecs-fargate module . Contribute to zkfmapf123/terraform-donggyu-ecs-fargate development by creating an account on GitHub.
github.com
https://github.com/zkfmapf123/terraform-donggyu-alb
GitHub - zkfmapf123/terraform-donggyu-alb: terraform alb module
terraform alb module. Contribute to zkfmapf123/terraform-donggyu-alb development by creating an account on GitHub.
github.com
Terraform을 효율적으로 사용하는 방법 (나만의 생각)
한번 더 추상화?
위에 여러가지 기재했지만, 테라폼은 장점이 많고 IaC 도구이다.
그리고 OpenSouce를 어떻게 사용하냐에 따라 더 효율적으로 구성할 수 있다.
하지만 최근 어떠한 고민으로 인해 테라폼을 효율적으로 사용하는 방법에 대해서 다시한번 고민해보게 되었다.
개발팀 : 저도 테라폼 활용해서 인프라 배포해고 싶어요
나 : 아 그래요? 테라폼 사용해보신 적 있나요?
개발팀 : 아뇨... 많이 어렵나요?
나 : 아뇨. 그렇게 어렵진 않습니다 (장 / 단점 설명 ...)
나 : 모듈은 이미 만들어 놨으니 한번 만들어 보시죠
개발팀 : 이거 md 파일로도 이해가 잘 안됩니다.
나 : 설명중...
개발팀 : 이거 variables 어떻게 작성해야 되요?
나 : 설명중...
개발팀 : 이거 어떤 값을 넣어야 해요?
나 : 설명중...
개발팀 : 이거 실행은...
나 : 설명중...
개발팀 : ㅠㅠ
사실 내가 울고싶다.
생각해보면 간단한 문제였다. 진짜 테라폼을 모르는사람은 모듈을 잘 구성했던, md파일을 잘 구성했던...
모르는건 모르는거다.
그럼 이 문제를 어떻게 고려해봐야할까?
그 과정에서 아래와같은 도구를 봤다.
https://aws.github.io/copilot-cli/
AWS Copilot CLI
Networking Service discovery is setup by default for your services to connect to each other.
aws.github.io
aws copilot cli를 보면 결국 cloudformation을 한번더 golang으로 추상화하였다.
cloud-formation을 왜 사용하니, 별로니 이 문제를 삼기보다 해당 도구를 사용하는 방법은 꽤나 충격이었다.
yaml code 내에서, 정해진 규칙에 따라 기재한다면 인프라를 구성할 수 있었다.
어쩌면 테라폼 모듈에 대해서 variables로 잘 감싼다고 해서 모든 사람들이 쉽게 사용할 수 있을까? 는 내 욕심일 수 도 있다.
그래서 여기서 말하고 싶은 바는,
결국 테라폼도 인프라를 구성하는 하나의 언어이고...
그런 테라폼을 한번더 추상화하는 모델을 만든다면...
실제로 사용하는 사람은 테라폼을 아무것도 모르지만 잘 활용할 수 있는 방법이 있을까? 이 물음에서 아래와 같은 실험과도 같은 프로젝트가 시작되었다.
프로젝트 이름 : Common Management Tool 설명 : AWS / DB 유저 관리에 대해서 테라폼으로 관리 관리 목록
AWS SSO (Identity Center) - User / Role / Policy MongoDB MYSQL / PostgreSQL Terraform Cloud User / Team Management
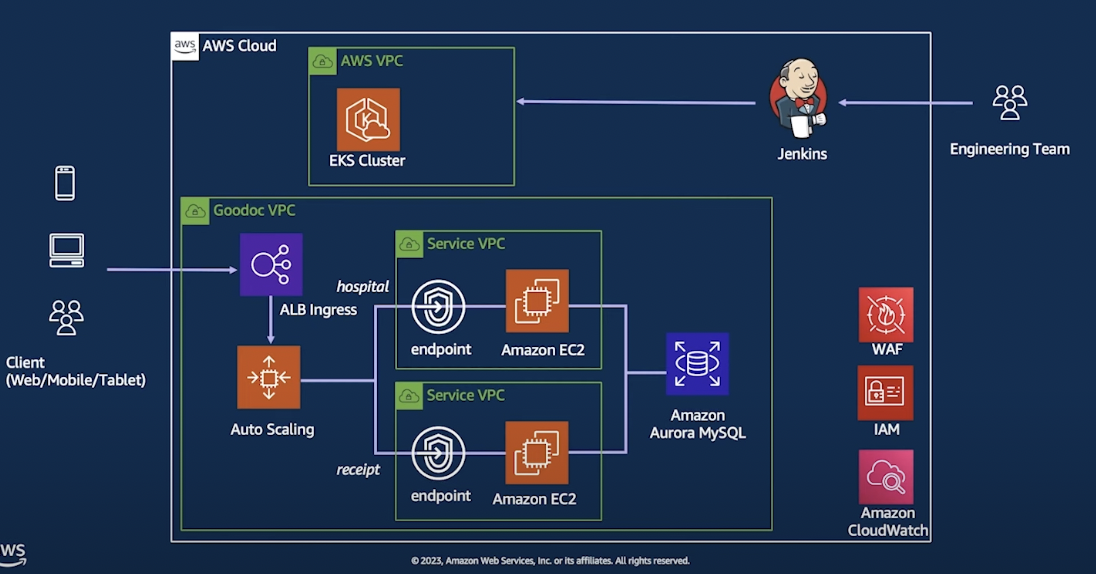
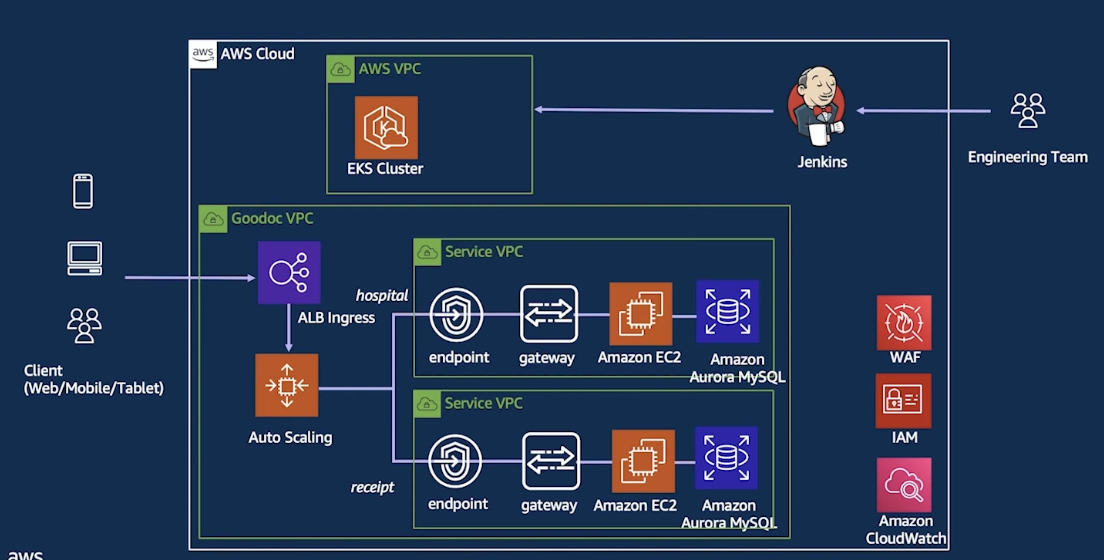
Architecture는 아래와 같다.
즉, 하나의 파일을 활용해서 모든 인프라 구성에 유저 생성 / 권한 변경을 한번에 해결하는 구성이다.
파일 내용은 아래와 같다.
dobby:
display_name: dobby lee
email: zkfmapf999@gmail.com
given_name: dobby
family_name: lee
group: admin
role:
shared:
- administrator
- security
- data-admin
- data-writer
- data-viewer
- developer-squad
- developer-service
- resource-reader
- zent-sso
dev:
- administrator
- security
- data-admin
- data-writer
- data-viewer
- developer-squad
- developer-service
- resource-reader
- zent-sso
prd:
- administrator
antman:
- administrator
data:
- administrator
lab:
- administrator
alpha:
- administrator
db:
prd-rds-cluster:
- ADMIN
mongodb:
dev-mongo:
- admin
prd-cluster:
- admin
rnd-cluster:
- admin
이 구성에서 핵심은 yaml 파일내에 기재된 옵션을 어떻게 parsing 해서 테라폼으로 활용하냐 인것같다.
해당 형태를 통해서 아래와 같은 부분이 해결되었다.
장점
유저 권한 변경 / 생성 관리 용이
신규 입사자 및 퇴사자 관리 용이
Team / Chapter 마다 동일한 규칙 명명
단점
테라폼 코드 어려워짐 (yaml -> decode -> terraform)
yaml 을 어려워하는 사람도 더러 존재함
자세한 부분은 추후 기재...